
 Netty粘包拆包
Netty粘包拆包
# 什么是 TCP 粘包半包?
TCP是一个流协议,就是没有界限的一长串二进制数据。TCP作为传输层协议并不不了解上层业务数据的具体含义,它会根据TCP缓冲区
的实际情况进行数据包的划分,所以在业务上认为是一个完整的包,可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成
一个大的数据包发送,这就是所谓的TCP粘包和拆包问题。面向流的通信是无消息保护边界的。
如下图所示,client发了两个数据包D1和D2,但是server端可能会收到如下几种情况的数据。
假设客户端分别发送了两个数据包 D1 和 D2 给服务端,由于服务端一次读取到的字节数是不确定的,故可能存在以下 4 种情况。
(1)服务端分两次读取到了两个独立的数据包,分别是 D1 和 D2,没有粘包和拆包;
(2)服务端一次接收到了两个数据包,D1 和 D2 粘合在一起,被称为 TCP 粘包;
(3)服务端分两次读取到了两个数据包,第一次读取到了完整的 D1 包和 D2 包的部分内容,第二次读取到了 D2 包的剩余内容,这被称为 TCP 拆包;
(4)服务端分两次读取到了两个数据包,第一次读取到了 D1 包的部分内容 D1_1,第二次读取到了 D1 包的剩余内容 D1_2 和 D2 包的整包。 如果此时服务端 TCP 接收滑窗非常小,而数据包 D1 和 D2 比较大,很有可能会发生第五种可能,即服务端分多次才能将 D1 和 D2 包接收完全,期间发生多次拆包。
# TCP 粘包/半包发生的原因
由于 TCP 协议本身的机制(面向连接的可靠地协议-三次握手机制)客户端与服务器会维持一个连接(Channel),数据在连接不断开的情况下,可以持续不断地将多个数据包发往服务器,但是如果发送的网络数据包太小,那么他本身会启用 Nagle 算法(可配置是否启用)对较小的数据包进行合并(基于此,TCP 的网络延迟要 UDP 的高些)然后再发送(超时或者包大小足够)。那么这样的话,服务器在接收到消息(数据流)的时候就无法区分哪些数据包是客户端自己分开发送的,这样产生了粘包;服务器在接收到数据库后,放到缓冲区中,如果消息没有被及时从缓存区取走,下次在取数据的时候可能就会出现一次取出多个 数据包的情况,造成粘包现象。
UDP:本身作为无连接的不可靠的传输协议(适合频繁发送较小的数据包),他不会对数据包进行合并发送(也就没有 Nagle 算法之说了),他直接是一端发送什么数据,直接就发出去了,既然他不会对数据合并,每一个数据包都是完整的(数据+UDP 头+IP 头等等发一 次数据封装一次)也就没有粘包一说了。
分包产生的原因就简单的多:可能是 IP 分片传输导致的,也可能是传输过程中丢失部分包导致出现的半包,还有可能就是一个包可能被分成了两次传输,在取数据的时候,先取到了一部分(还可能与接收的缓冲区大小有关系),总之就是一个数据包被分成了多次接收。
更具体的原因有三个,分别如下:
- 应用程序写入数据的字节大小大于套接字发送缓冲区的大小
- 进行 MSS 大小的 TCP 分段。MSS 是最大报文段长度的缩写。MSS 是 TCP 报文段中的数据字段的最大长度。数据字段加上 TCP 首部才等于整个的 TCP 报文段。所以 MSS 并不是 TCP 报文段的最大长度,而是:MSS=TCP 报文段长度-TCP 首部长度
- 以太网的 payload 大于 MTU 进行 IP 分片。MTU 指:一种通信协议的某一层上面所能通过的最大数据包大小。如果 IP 层有一个数据包要传,而且数据的长度比链路层的 MTU 大, 那么 IP 层就会进行分片,把数据包分成托干片,让每一片都不超过 MTU。注意,IP 分片可以发生在原始发送端主机上,也可以发生在中间路由器上。
# 解决方案
由于底层的 TCP 无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重组的,这个问题只能通过上层的应用协议栈设计来解决,根据业界的主流协议的解决方案, 可以归纳如下:
消息定长度,传输的数据大小固定长度,例如每段的长度固定为100字节,如果不够空位补空格,netty 提供了FixedLengthFrameDecoder(固定长度报文来分包)
ch.pipeline().addLast(new FixedLengthFrameDecoder(FixedLengthEchoClient.REQUEST.length()));1
2在数据包尾部添加特殊分隔符,比如下划线,中划线等,这种方法简单易行,但选择分隔符的时候一定要注意每条数据的内部一定不能出现分隔符。LineBasedFrameDecoder (回车换行分包)、DelimiterBasedFrameDecoder(特殊分隔符分包)
// 回车换行符
ch.pipeline().addLast(new LineBasedFrameDecoder(1024));
ch.pipeline().addLast(new LineBaseServerHandler());
// LineBaseServerHandler
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf in = (ByteBuf)msg;
String request = in.toString(CharsetUtil.UTF_8);
System.out.println("Server Accept["+request
+"] and the counter is:"+counter.incrementAndGet());
String resp = "Hello,"+request+". Welcome to Netty World!"
+ System.getProperty("line.separator");
ctx.writeAndFlush(Unpooled.copiedBuffer(resp.getBytes()));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 自定义分隔符
public static final String DELIMITER_SYMBOL = "@~";
ByteBuf delimiter = Unpooled.copiedBuffer(DELIMITER_SYMBOL.getBytes());
ch.pipeline().addLast(new DelimiterBasedFrameDecoder(1024, delimiter));
ch.pipeline().addLast(new DelimiterServerHandler());
// DelimiterServerHandler
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf in = (ByteBuf) msg;
String request = in.toString(CharsetUtil.UTF_8);
System.out.println("Server Accept["+request
+"] and the counter is:"+counter.incrementAndGet());
String resp = "Hello,"+request+". Welcome to Netty World!" + DelimiterEchoServer.DELIMITER_SYMBOL;
ctx.writeAndFlush(Unpooled.copiedBuffer(resp.getBytes()));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度) 的字段,通常设计思路为消息头的第一个字段使用 int32 来表示消息的总长度,使用 LengthFieldBasedFrameDecoder,这种方式最常用。
LengthFieldBasedFrame 详解
LengthFieldBasedFrame 包含四个参数:
maxFrameLength:表示的是包的最大长度;
lengthFieldOffset:指的是长度域的偏移量,表示跳过指定个字节之后的才是长度域;
lengthFieldLength:记录该帧数据长度的字段,也就是长度域本身的长度;
lengthAdjustment:长度的一个修正值,可正可负,Netty 在读取到数据包的长度值 N 后, 认为接下来的 N 个字节都是需要读取的,但是根据实际情况,有可能需要增加 N 的值,也有可能需要减少 N 的值,具体增加多少,减少多少,写在这个参数里;
initialBytesToStrip:从数据帧中跳过的字节数,表示得到一个完整的数据包之后,扔掉这个数据包中多少字节数,才是后续业务实际需要的业务数据。
failFast:如果为 true,则表示读取到长度域,TA 的值的超过 maxFrameLength,就抛出一个 TooLongFrameException,而为 false 表示只有当真正读取完长度域的值表示的字节之后,才会抛出 TooLongFrameException,默认情况下设置为 true,建议不要修改,否则可能会造成内存溢出。
下面通过几个例子来理解LengthFieldBasedFrame
1、数据包大小: 14B =长度域 2B + "HELLO, WORLD"(单词 HELLO+一个逗号+一个空格+单词 WORLD 占12B)

lengthFieldOffset = 0 lengthFieldLength = 2 lengthAdjustment = 0 (无需调整) initialBytesToStrip = 0 (解码过程中,没有丢弃任何数据)
2、数据包大小: 14B =长度域2B + "HELLO, WORLD

长度域的值为 12B(0x000c)。解码后,希望丢弃长度域 2B 字段,所以,只要 initialBytesToStrip = 2 即可。
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = 0 无需调整
initialBytesToStrip = 2 解码过程中,丢弃 2 个字节的数据
3、数据包大小: 14B =长度域 2B + "HELLO, WORLD"。长度域的值为14(0x000E)

长度域的值为 14(0x000E),包含了长度域本身的长度。希望解码后保持一样,根据上面的公式,参数应该为:
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = -2 因为长度域为 14,而报文内容为 12,为了防止读取报文超出报文本体,和将长度字段一起读取进来,需要告诉 netty,实际读取的报文长度比长度域中的要少 2(12-14=-2)
initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
4、在长度域前添加2个字节的Header。长度域的值(0x00000C) = 12。总数据包长度**😗* 17=Header(2B) + 长度域(3B) + "HELLO, WORLD"

长度域的值为 12B(0x000c)。编码解码后,长度保持一致,所以 initialBytesToStrip = 0。 参数应该为:
lengthFieldOffset = 2
lengthFieldLength = 3
lengthAdjustment = 0 无需调整
initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
5、Header与长度域的位置换了。总数据包长度: 17=长度域(3B) + Header(2B) + "HELLO,WORLD"

长度域的值为 12B(0x000c)。编码解码后,长度保持一致,所以 initialBytesToStrip = 0。 参数应该为:
lengthFieldOffset = 0
lengthFieldLength = 3
lengthAdjustment = 2 因为长度域为 12,而报文内容为 12,但是我们需要把 Header 的值一起读取进来,需要告诉 netty,实际读取的报文内容长度比长度域中的要多 2(12+2=14)
initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
6、带有两个 header。HDR1丢弃,长度域丢弃,只剩下第二个header 和有效包体,这种协议中,一般HDR1可以表示magicNumber表示应用只接受以该 magicNumber 开头的二进制数据,rpc 里面用的比较多。总数据包长度: 16=HDR1(1B)+长度域(2B) +HDR2(1B) + "HELLO,WORLD"

长度域的值为 12B(0x000c)
lengthFieldOffset = 1 (HDR1 的长度)
lengthFieldLength = 2
lengthAdjustment =1 因为长度域为 12,而报文内容为 12,但是我们需要把 HDR2 的值一起读取进来,需要告诉 netty,实际读取的报文内容长度比长度域中的要多 1(12+1=13)
initialBytesToStrip = 3 丢弃了 HDR1 和长度字段
7、带有两个header,HDR1 丢弃,长度域丢弃,只剩下第二个header 和有效包体。总数据包长度: 16=HDR1(1B)+长度域(2B) +HDR2(1B) + "HELLO, WORLD"
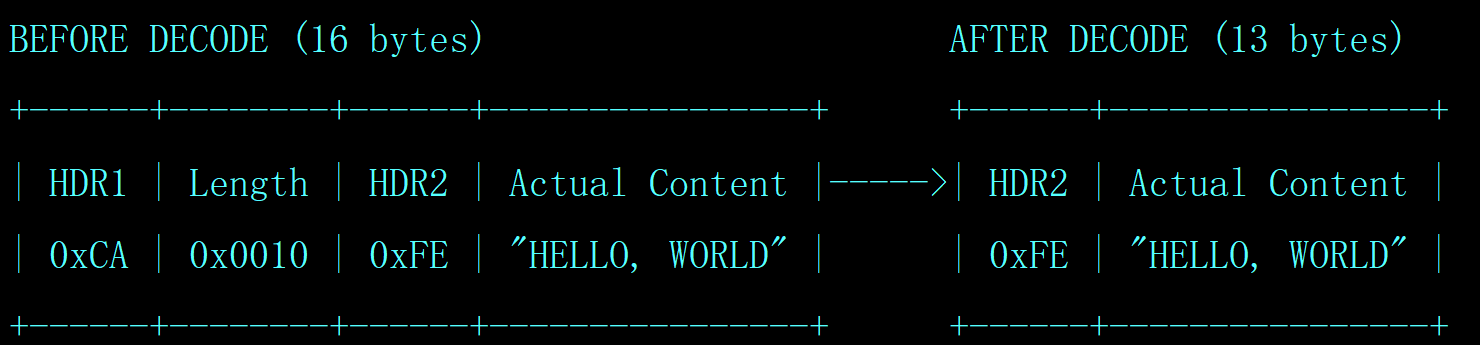
长度域的值为 16B(0x0010),长度为 2,HDR1 的长度为 1,HDR2 的长度为 1,包体的长度为 12,1+1+2+12=16。
lengthFieldOffset = 1
lengthFieldLength = 2
lengthAdjustment = -3 因为长度域为 16,需要告诉 netty,实际读取的报文内容长度比长度域中的要 少 3(13-16= -3)
initialBytesToStrip = 3 丢弃了 HDR1 和长度字段
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06