
 秒杀系统扣减库存
秒杀系统扣减库存
# 库存扣减关键技术点
- 同一个 SKU,库存数量是共享
- 剩余库存要大于等于本次扣减的数量,否则会出现超卖现象,引发资损
- 对同一个数量多用户并发扣减时,要注意并发安全,保证数据的一致性
- 类似于秒杀这样高 QPS 的扣减场景,要保证性能与高可用
- 对于购物车下单场景,多个商品库存批量扣减,要保证事务
- 如果有交易退款,保证库存扣减可以返还:返还的数据总量不能大于扣减的总量;返还要保证幂等;可以分多次返还。
# 数据库扣减方案
在商品购买的过程中,库存的抵扣过程,一般操作如下:
- select根据商品id查询商品的库存。
- 根据下单的数量,计算库存是否足够,如果存库不足则抛出库存不足的异常,如果库存足够,则减去扣除的库存得到最新的库存剩余值。
- set设置最新的库存剩余值。
上述过程的伪代码如下:
// 根据商品id获取商品剩余库存
select stock_remaing from stock_table where id=${goodsId};
// 操作库存
// 比较库存
if(stock_remaing <quantity){
// 抛出库存不足的异常
}
else{
// 抵扣以后的库存值
int new_stock=stock_remaing - quantity;
}
// 根据商品id设置计算后的库存
update stock_table set stock_remaing =${new_stock} id=${goodsId};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
一般来说,从数据库层面讲,库存业务会分为两步,第一步是插入一条记录到扣减明细表inventory_detail,第二步是对库存扣减表inventory的一条记录进行扣减,这两步往往是在一个事务中实现的。
如果数据库事务的隔离级别不是串行化(serializable),根据事务的特性,在并发修改的时候,可能会出现写覆盖的问题。
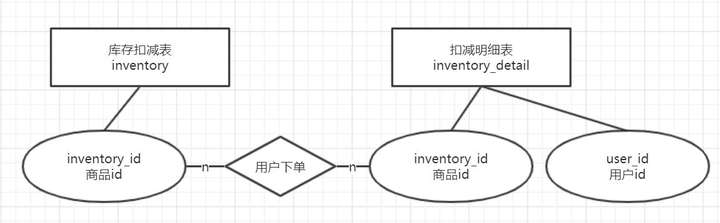
并发修改数据库存超卖
如果数据库事务的隔离级别不是串行化(serializable),根据事务的特性,在并发修改的时候,可能会出现写覆盖的问题。
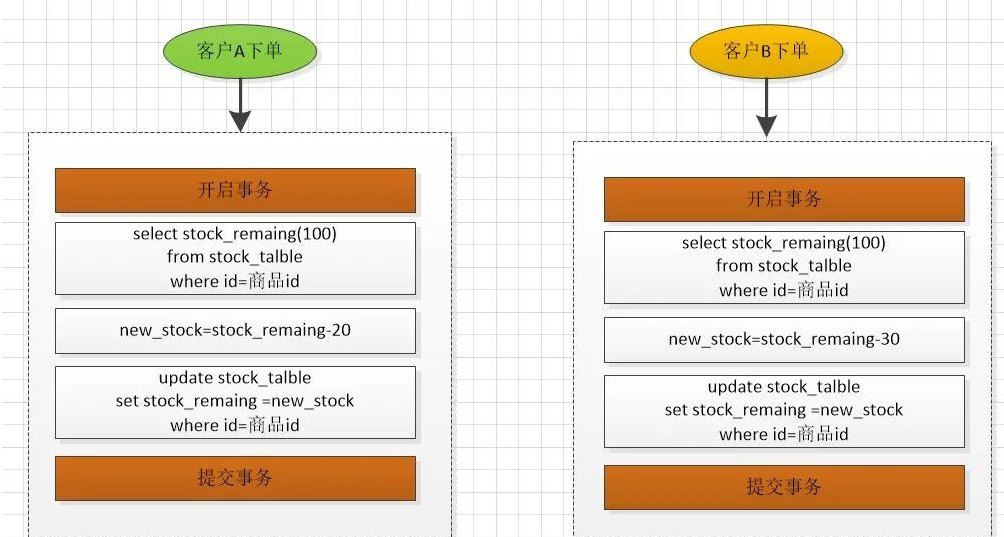
假设,商品的剩余库存stock_remaing 为100,客户A下单20,客户B下单30,在并发扣库存的时候,可能存在超卖。如果客户A和客户B同时获取剩余库存为100,则会出现事务后提交的值会覆盖前一个客户提交的值,有可能剩余的库存是80或者70。流程如下:
依赖的数据库特性:
- 依赖数据库的乐观锁(比如:版本号或者库存数量)保证数据并发扣减的强一致性
- 借助事务特性,针对购物车下单批量扣减时,部分扣减失败,数据回滚
# 数据库悲观锁更新库存
为了在事务控制中,防止写覆盖,你会想到使用select for update的方式,将该商品的库存锁住,然后执行余下的操作。
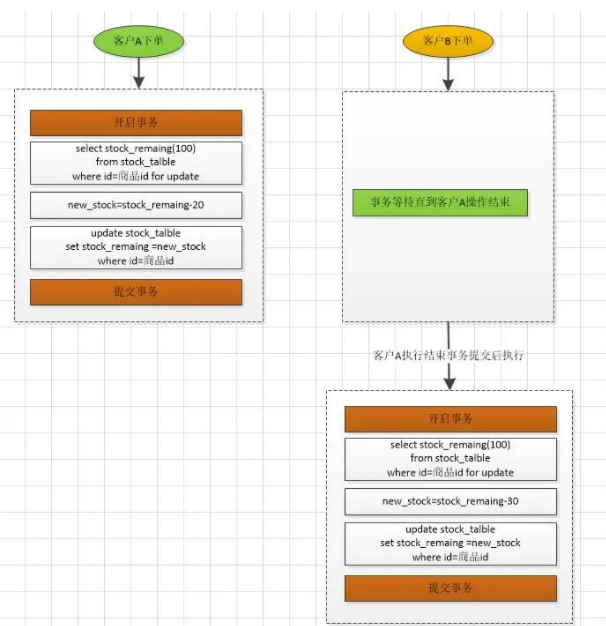
使用悲观锁方式,如果并发情况比较高的时候,扣减库存的操作是串行操作,效率很低。
# 使用乐观锁更新库存
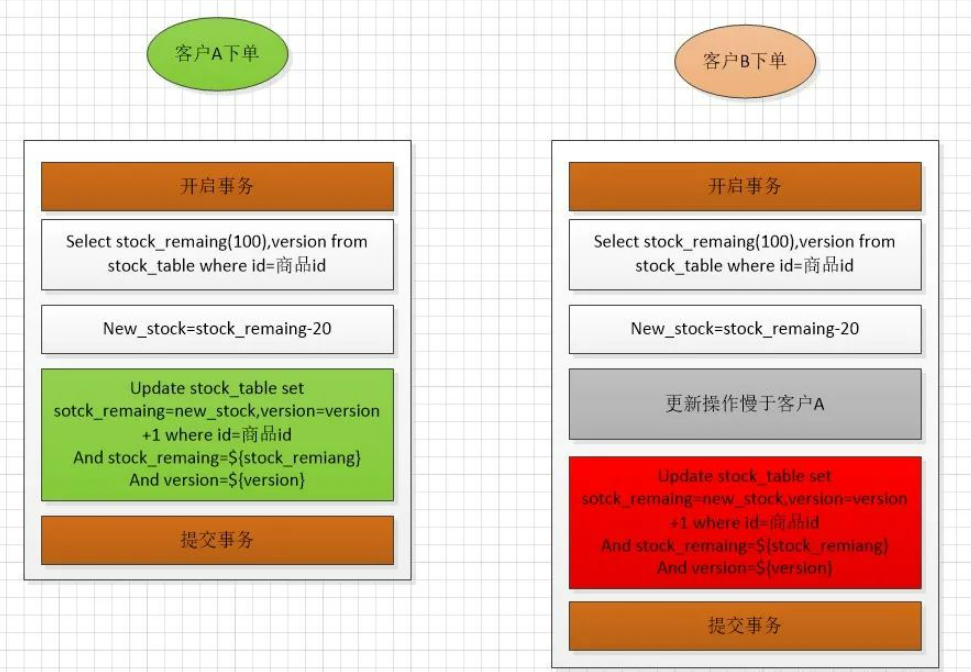
在更新的时候,使用(CAS+版本号更新)+重试条件(重试次数或者重试时间限制)乐观锁的方式更新库存。此时,如果,客户A和客户B同时读取到库存剩余100,在更新的时候,有一个操作会失败。流程如下:
还可以这样扣库存:
update stock_table
set stock_remaing = stock_remaing - #{count}
where sku_id='123' and stock_remaing >= #{count}
2
3
此 SQL 采用数据库自带行锁机制,在 where 条件里判断此次购买的数量小于等于剩余的数量。
在扣减服务的代码里,判断此 SQL 的返回值,如果值为 1 ,表示扣减成功。否则,返回 0 ,表示库存不足,需要回滚。
举个极端的例子:最新款 iPhone 秒杀,库存只有 5 件,活动期间峰值 QPS 预估在 10W,活动结束后,上面的流水表最终只会插入 5 条记录,但是查询的 QPS 却接近 10W QPS,读的压力非常大。
所以,数据库扣减方案第一次升级主要是针对库存前置校验模块的优化,作为前置拦截器,承载的流量很大,如果将流量全部压到主库上,很容易把数据压垮。我们考虑把数据库架构升级。
【数据库扣减方案】升级
采用了读写分离方式,新增加了一套从库,借助 MySQL 自带的数据同步能力。库存校验时读取从数据库。
当然,数据同步有一定的时间延迟,从库的数据新鲜度有一定的滞后性,所以这个库存校验结果并不一定准确,但却能拦截大部分的无效流量。
最终能不能成功购买,由主库的乐观扣减 SQL 来控制,并不会影响最终扣减的准确性。大大减轻主库的查询压力。
数据库方案的优点:
- 借助数据库的 ACID 特性,业务上不会出现超卖、少买现象
- 实现简单,如果项目工期紧张,或者开发资源不足情况下非常适用
数据库方案的不足:
- 如果参与秒杀的 SKU 非常多,最后的写操作都是基于库存主库,性能压力会比较大。
# 基于分库分表的扣减方案
为了解决单实例存在的容量和性能上限问题,我们还可以考虑将库存表进行水平拆分,分摊洪峰压力。主要通过数据的水平拆分实现不同商品的库存扣减请求路由到不同的数据库。基本数据库架构图如下
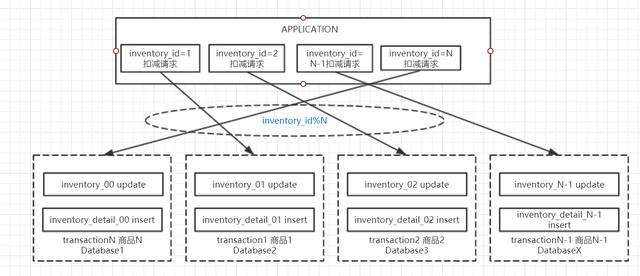
从上图不难看出,库存扣减表和扣减明细表一般都使用商品id作为片键,这样可以保证满足整个系统在高并发扣减请求的同时,同一商品的库存扣减操作和添加明细操作在同一个事务中实现。如果数据分布和业务请求足够均匀,理论上经过分库分表设计后,整个系统的吞吐量将会是线性的增长,主要取决于分实例的数量。
# redis扣减库存方案
引入了从库,确实能分摊主库很大一部分压力,但是面对秒杀这种万级 QPS 流量,MySQL 的千级 TPS 根本支撑不了,需要进一步升级读取的性能。
此时引入缓存中间件(如 Redis),将 MySQL 的数据定时同步到缓存中,库存校验模块,从 Redis 中查询剩余的库存数据。由于缓存基于内存操作,性能比数据库高出几个数量级,单台 Redis 实例可以达到 10W QPS 的读性能。
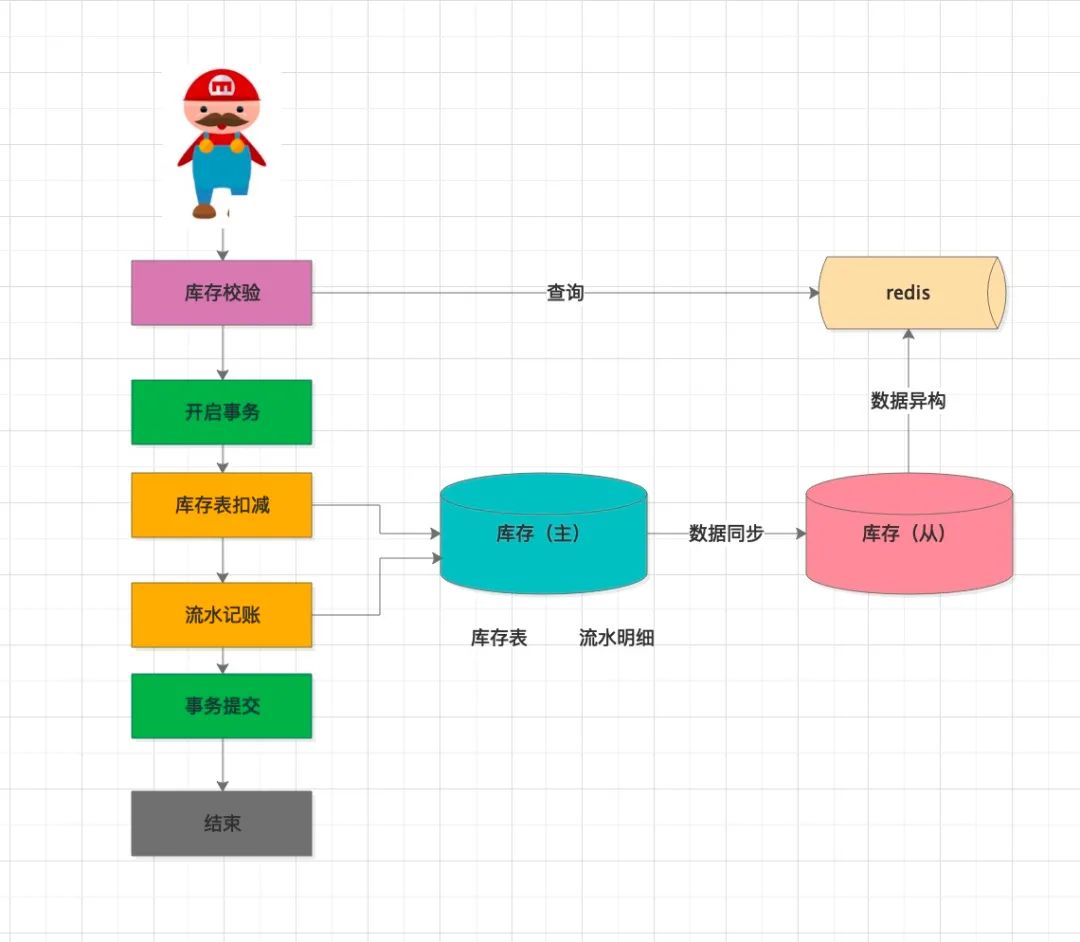
下面,我们来看看基于 Redis 如何来设计库存扣减?
剩余库存(k-v结构):
key:sku_leaved_amount_{sku_id}
value:剩余的库存数值
流水(hash结构):
key:inventory_flow_{sku_id}
hash—key:订单明细id(不同业务场景的全局性id,用来做幂等控制)
hash—value:本次购买的数量
2
3
4
5
6
7
8
对于购物车下单,要执行多个Redis命令。但是多个 Redis 命令无法保证原子性。
我们可以采用 Lua 脚本形式,将这些命令打包到一个脚本中,作为一个命令发送给 Redis 执行,从而保证了原子性。
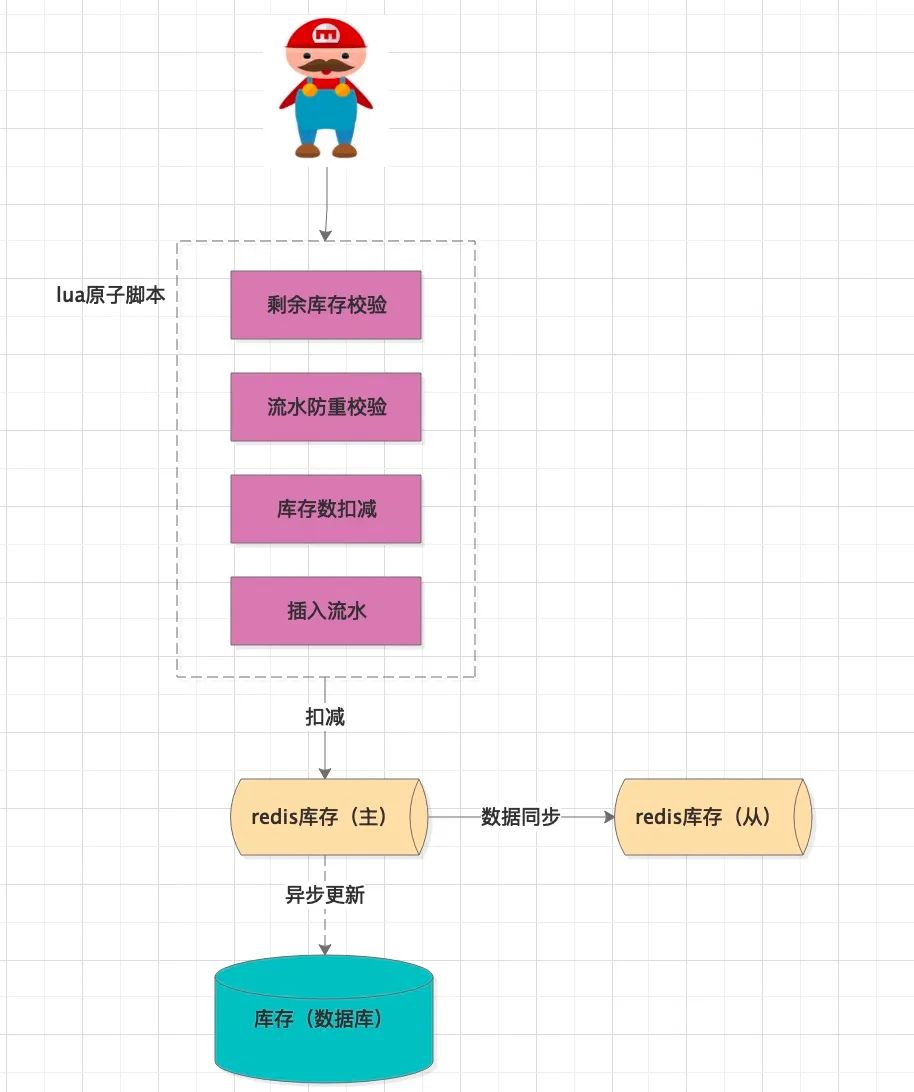
当 Redis 扣减成功后,应用程序再将此次扣减异步化保存到数据库中,持久化存储,毕竟 Redis 只是临时性存储,有宕机风险,会丢失数据。
# 基于缓存的分桶扣减方案
在更大规模,针对单一商品的超高并发扣减的库存集群中,可能基于数据库内核的改造优化还无法满足业务需求。单一商品的超高并发扣减可能会影响到同一数据库实例上的其他商品扣减,同一个数据库实例上也可能存在多个热点商品造成互相影响,这时就需要考虑在业务和数据库架构上再做一次升级,我们引入基于缓存的分桶扣减方案。
超大热点商品,针对该商品再做多key拆分,先走弱幂等性的缓存扣减,缓存扣减后,异步往DB写入一条库存流水记录,后续再做缓存与数据库的库存总量同步。
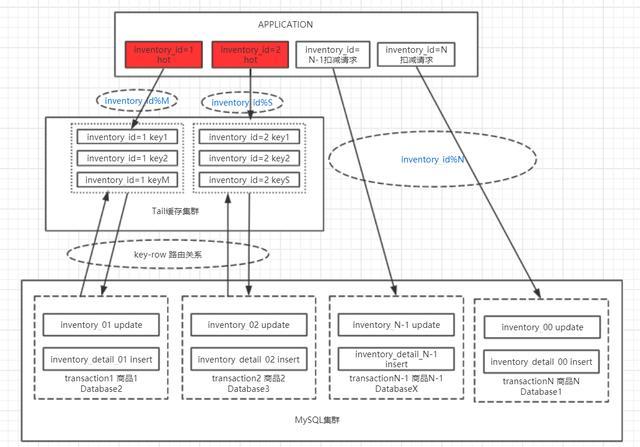
我们采取的库存分片设计。通过将秒杀商品的库存进行“分割”存储来提升Redis的读写并发量。
分桶管理
为了更通俗和直观的描述,缓存集群的一个key就对应于于一个"分桶"。要实现一个基于缓存分桶方案的高扩展性的库存系统,分桶的设计至关重要,比如一个热点商品应该对应多少个分桶,分桶的数量能否根据当前的业务变化做到弹性的伸缩
- 1、分桶预分配库存:当分桶初始化后,每个分桶应该保存多少库存量。不一定在预分配库存阶段将该商品的库存数量从DB全部分配到缓存中,可能是一种渐进式的分配策略,DB作为库存总池子
- 2、分桶扩容/缩容:分桶数量的变化,扩缩容操作本质上是调整桶映射管理内的信息,加入或者减少桶,桶信息一旦增加或者减少了,扣减链路会秒级感知到,然后将用户流量引导或者移除出去。从上面的DB架构图可以看出,比较简单的实现方式就是根据当前热点商品的桶数量取模
- 3、桶内库存数量扩容/缩容:即每个分桶内该商品的库存数量变化,扩容场景主要用于当该分桶内库存接近扣减完成时,系统自动去MySQL库存集群总池子里捞一部分过来放进桶内。缩容场景主要场景在于桶下线后将桶内剩余的库存回收到库存总池子中
- 4、合并展示:在基于缓存的分桶设计中,由于同一种热点商品拆分成了多个key,所以在前端界面展示上同样会带来挑战,需要做库存的合并
# 其他解决方案
1、单条 SKU 库存记录更新过热,也可以采用批量提交方式,将多次扣减累计计数,集中成一次扣减,从而实现了将串行处理变成了批处理,也可以大大减轻数据库压力。
2、引入 RocketMQ 消息队列,经过前置校验后,如果有剩余库存,则把创建订单的操作封装成消息发送给 MQ,订单系统从 RocketMQ 中以特定的频率消费,创建订单,该方案有一定的延迟性。
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06