
 消息中间件入门教程
消息中间件入门教程
# 消息中间件(MQ)的定义
MQ:MessageQueue,消息队列。 队列,是一种FIFO 先进先出的数据结构。消息由生产者发送到MQ进行排队,然后按原来的顺序交由消息的消费者进行处理。
一般认为,消息中间件属于分布式系统中一个子系统,关注于数据的发送和接收,利用高效可靠的异步消息传递机制对分布
式系统中的其余各个子系统进行集成。
**高效:**对于消息的处理处理速度快。
**可靠:**一般消息中间件都会有消息持久化机制和其他的机制确保消息不丢失。
**异步:**指发送完一个请求,不需要等待返回,随时可以再发送下一个请求,既不需要等待。
# 为什么要用消息中间件?
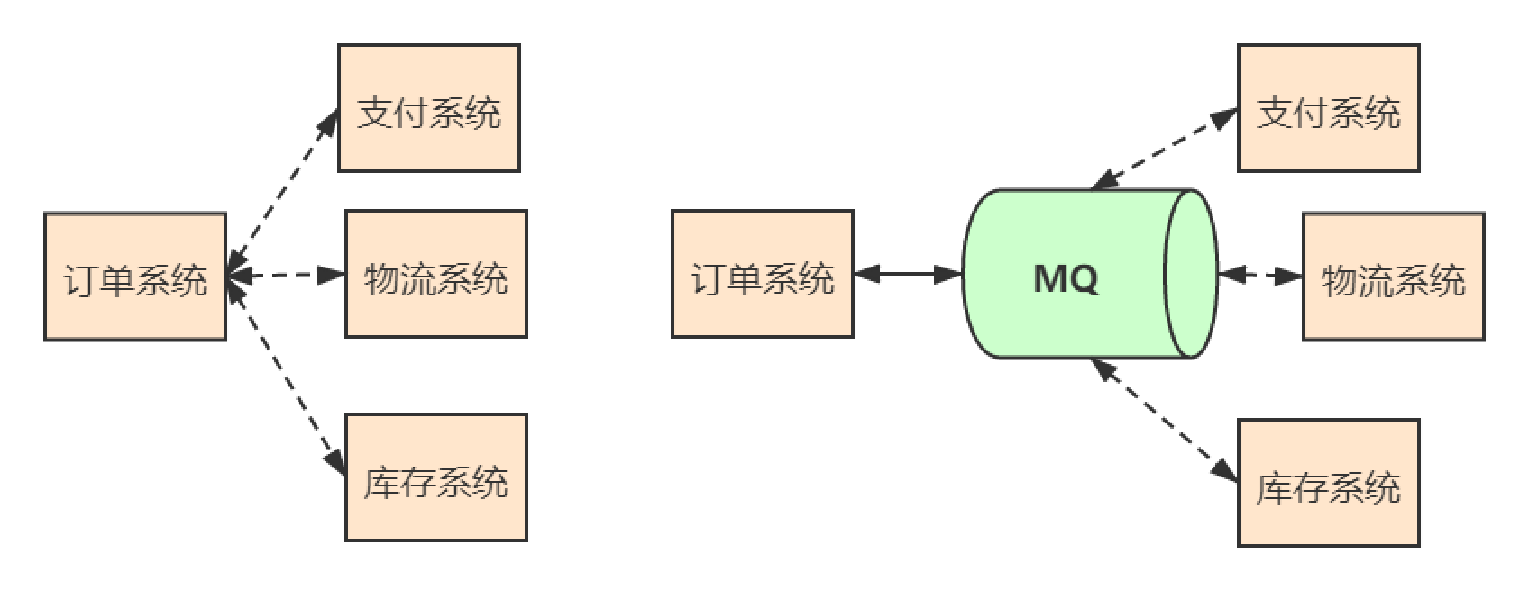
应用解耦
系统的耦合性越高,容错性就越低。以电商应用为例,用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障或者 因为升级等原因暂时不可用,都会造成下单操作异常,影响用户使用体验 。
使用消息中间件,系统的耦合性就会提高了。比如物流系统发生故障,需要几分钟才能来修复,在这段时间内,物流系统要处理的数据被缓存到消息队列中,用户的下单操作正常完成。当物流系统恢复后,继续处理存放在消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故障。
异步处理
异步能提高系统的响应速度、吞吐量。
比如购票系统,需求是用户在购买完之后能接收到购买完成的短信。
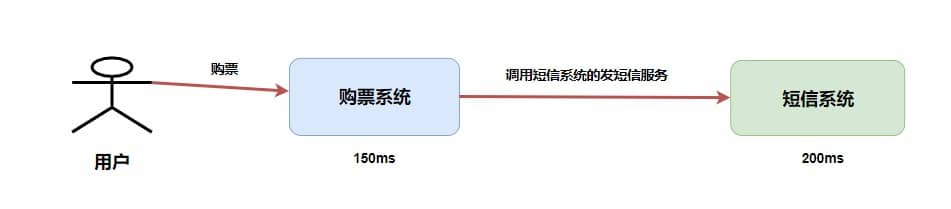
省略中间的网络通信时间消耗,假如购票系统处理需要 150ms ,短信系统处理需要 200ms ,那么整个处理流程的时间消耗就是 150ms + 200ms = 350ms。
短信系统又不是很有必要,它仅仅是一个辅助功能增强用户体验感而已。所以,可以使用异步操作。
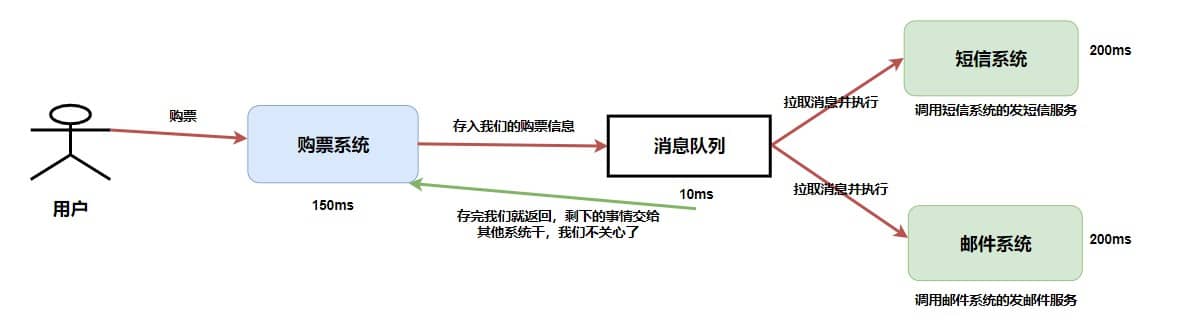
整个耗时只是 150ms + 10ms = 160ms。
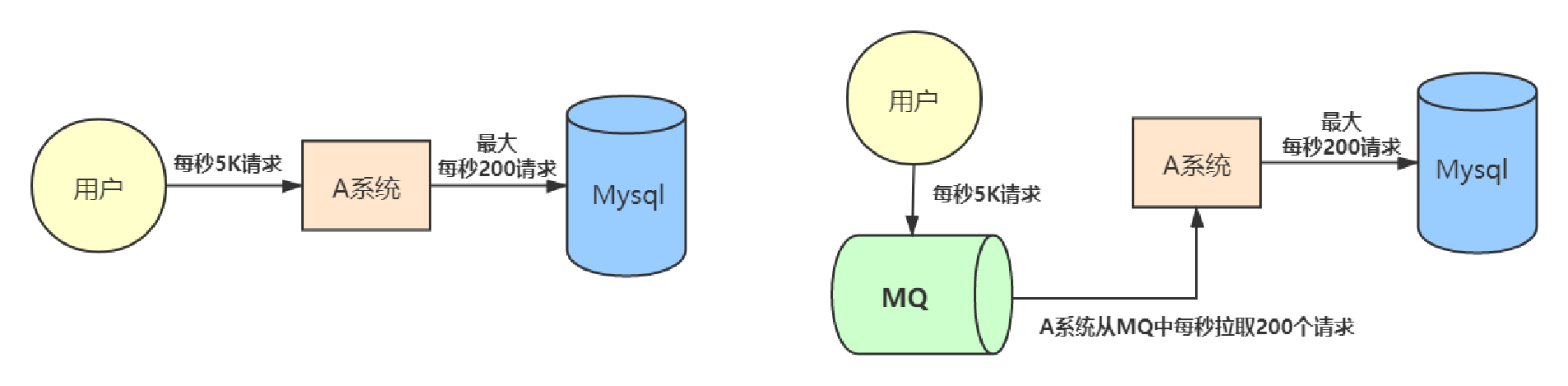
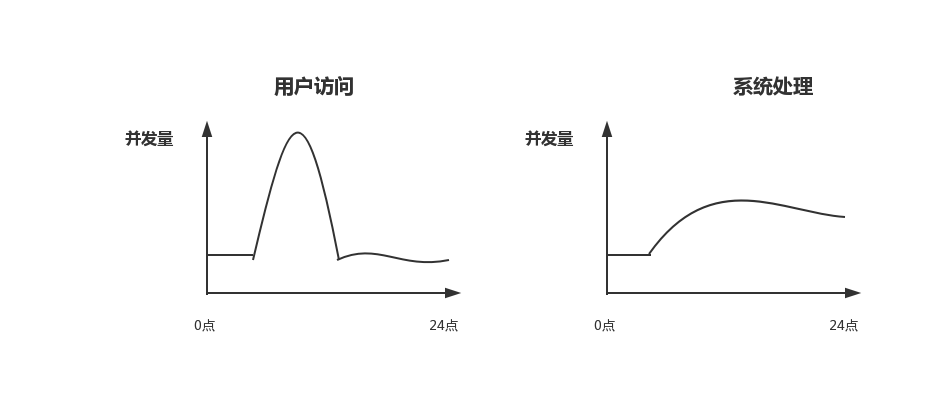
流量削峰
应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮。有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大大提到系统的稳定性和用户体验。
互联网公司的大促场景(双十一、店庆活动、秒杀活动)都会使用到 MQ。
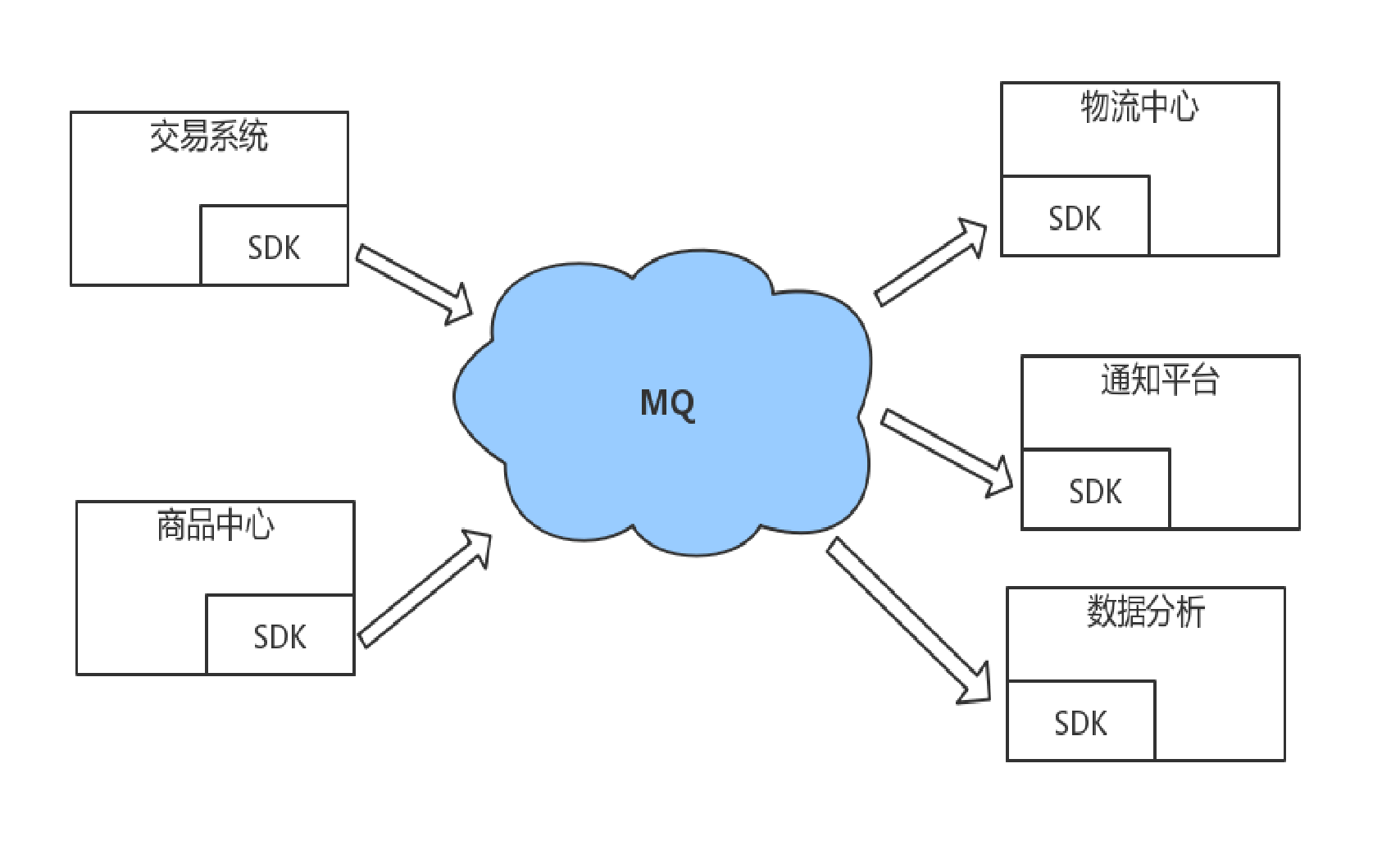
数据分发
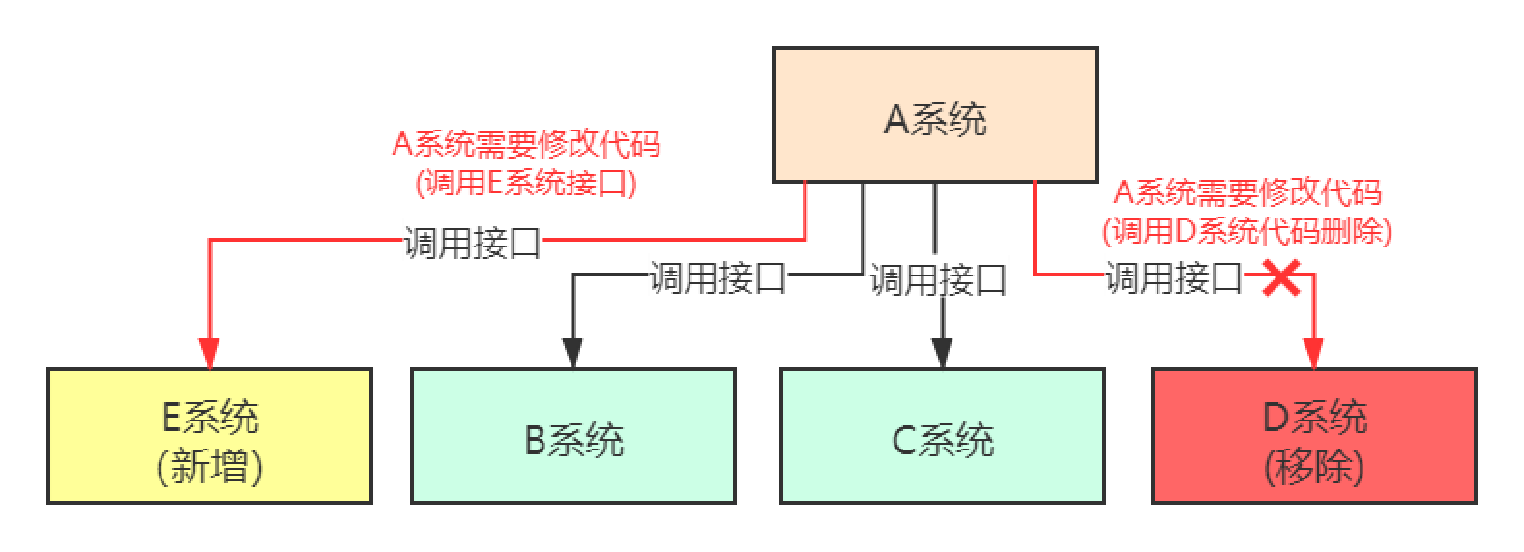
通过消息队列可以让数据在多个系统更加之间进行流通。数据的产生方不需要关心谁来使用数据,只需要将数据发送到消息队列,数据使用方直接在消息队列中直接获取数据即可。
接口调用的弊端,无论是新增系统,还是移除系统,代码改造工作量都很大。
使用 MQ 做数据分发好处,无论是新增系统,还是移除系统,代码改造工作量较小。
所以使用 MQ 做数据的分发,可以提高团队开发的效率。
日志处理
日志处理是指将消息队列用在日志处理中,比如 Kafka 的应用,解决大量日志传输的问题。架构简化如下:

日志采集客户端,负责日志数据采集,定时写入 Kafka 队列:Kafka 消息队列,负责日志数据的接收,存储和转发;日志处理应用:订阅并消费 kafka 队列中的日志数据;
# MQ的优缺点
上面MQ的所用也就是使用MQ的优点。 但是引入MQ也是有他的缺点的:
- 系统可用性降低
系统引入的外部依赖增多,系统的稳定性就会变差。一旦MQ宕机,对业务会产生影响。这就需要考虑如何保证MQ的高可用。
- 系统复杂度提高
引入MQ后系统的复杂度会大大提高。以前服务之间可以进行同步的服务调用,引入MQ后,会变为异步调用,数据的链路就会变得更复杂。并且还会带来其他一些问题。比如:如何保证消费不会丢失?不会被重复调用?怎么保证消息的顺序性等问题。
- 消息一致性问题
A系统处理完业务,通过MQ发送消息给B、C系统进行后续的业务处理。如果B系统处理成功,C系统处理失败怎么办?这就需要考虑如何保证消息数据处理的一致性。
- 重复消费消息
生产者可能把一条消息发送给broker两次,消费者可能消费一条消息两次。
- 消息丢失
在生产者、broker、消费者这三个角色中都有可能导致消息丢失。
- 消息堆积
有可能一瞬间流量大增,消费者消费不过来消息,或者消费者宕机了。
# MQ 产品比较
| ActiveMQ | RabbitMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 性能(单台) | 6000+ | 万级(12000+) | 十万级 | 百万级 |
| 消息持久化 | 支持 | 支持 | 支持 | 支持 |
| 多语言支持 | 支持 | 支持 | 很少 | 支持 |
| 社区活跃度 | 高 | 高 | 中 | 高 |
| 支持协议 | 多(JMS,AMQP….. ) | 多(AMQP,STOMP,MQTT….. ) | 自定义协议 | 自定义协议 |
| 综合评价 | 优点: 成熟,已经在很多公司得到应用。较多的文档。各种协议支持较好,有多个语言的成熟客户端。缺点:性能较弱。缺乏大规模吞吐的场景的应用,有江河日下之感。 | 优点:性能较好,管理界面较丰富,在互联网公司也有较大规模的应用,有多个语言的成熟客户端。缺点:内部机制很难了解,也意味很难定制和掌控。集群不支持动态扩展。 | 优点:模型简单,接口易用。在阿里有大规模应用。分布式系统,性能很好,版本更新很快。 缺点:文档少,支持的语言较少。 | 优点:天生分布式,性能最好,所以常见用于大数据领域。 缺点:运维难度大,偶尔有数据混乱的情况,对ZooKeeeper强依赖。多副本机制下对带宽有一定的要求。 |
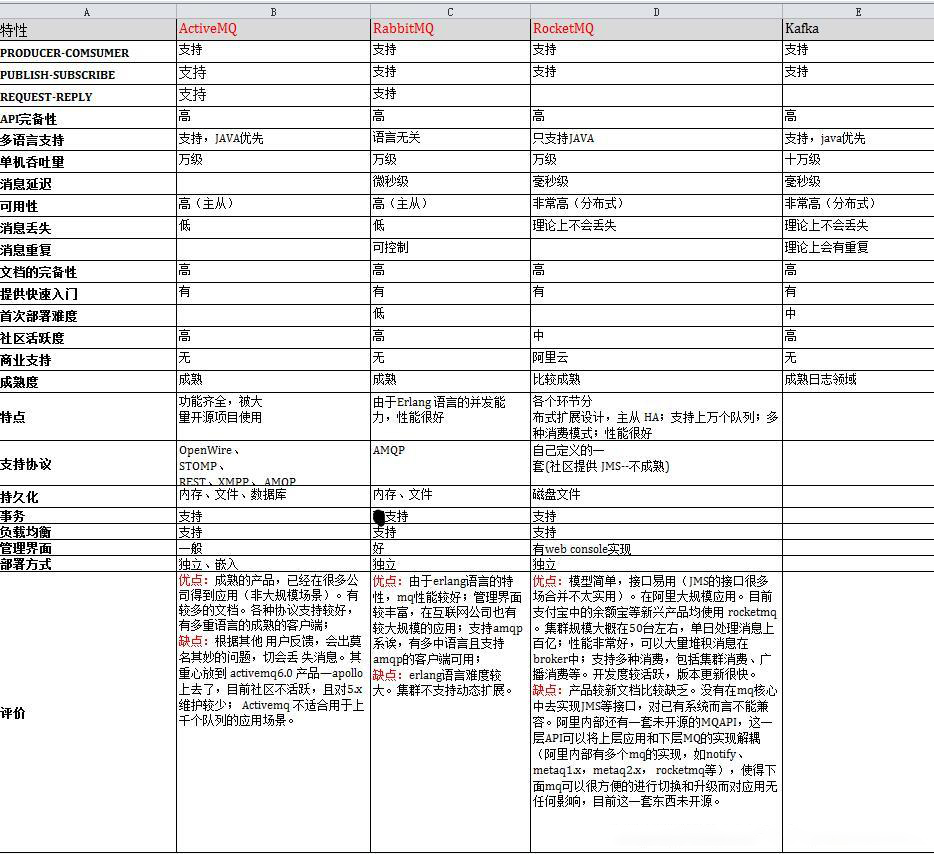
官方提供了一些不同于kafka的对比差异: https://rocketmq.apache.org/docs/motivation/
用户访问量在 ActiveMQ 的可承受范围内,而且确实主要是基于解耦和异步来用的,可以考虑 ActiveMQ,也比较贴近 Java 工程师的使用习惯,但是 ActiveMQ 现在停止维护了,同时 ActiveMQ 并发不高,所以业务量一定的情况下可以考虑使用。
RabbitMQ 作为一个纯正血统的消息中间件,有着高级消息协议 AMQP 的完美结合,在消息中间件中地位无可取代,但是 erlang 语言阻止了我们去深 入研究和掌控,对公司而言,底层技术无法控制,但是确实是开源的,有比较稳定的支持,活跃度也高。
对自己公司技术实力有绝对自信的,可以用 RocketMQ 。所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 ActiveMQ、RabbitMQ 是不错的选择;大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择 。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,几乎是全世界这个领域的事实性规范。
整体上来看,使用文件系统的消息中间件kafka、rokcetMq)性能是最好的,所以基于文件系统存储的消息中间件是发展趋势。(从存储方式和效率来看 文件系统>KV 存储>关系型数据库)
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06