
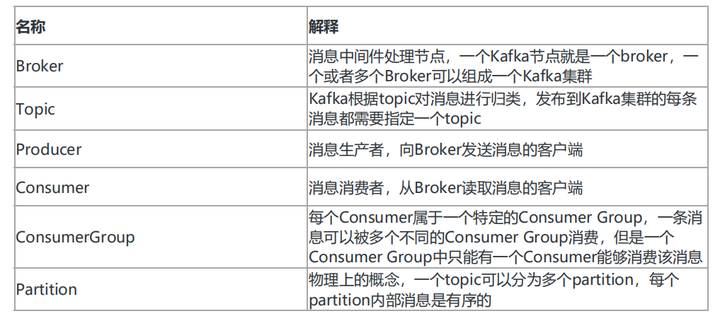
 Kafka 介绍
Kafka 介绍
# Kafka的使用场景
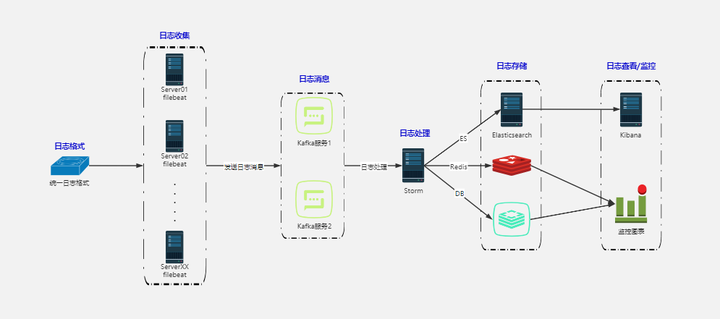
日志收集:一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式开放给各种 consumer,例如hadoop、Hbase、Solr、flink等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这 些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到 hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反 馈,比如报警和报告。
# Kafka基本概念
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。
producer通过网络发送消息到Kafka集群,然后consumer来进行消费,如下图:
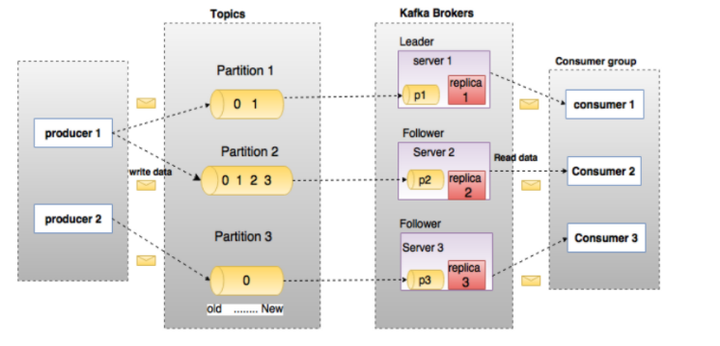
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
主题Topic和消息日志Log
可以理解Topic是一个类别的名称,同类消息发送到同一个Topic下面。对于每一个Topic,下面可以有多个分区(**Partition)**日志文件:
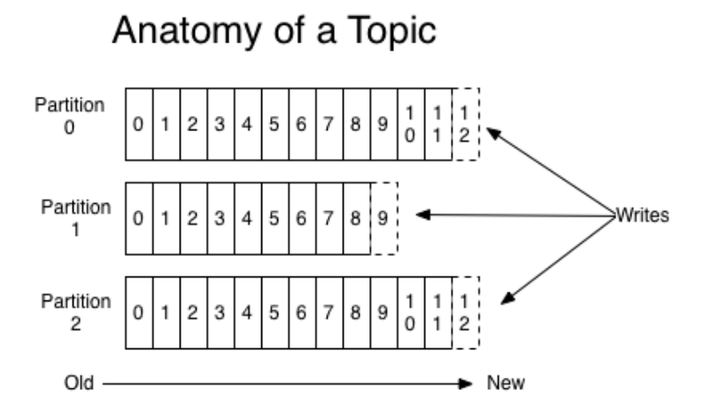
Partition是一个有序的message序列,这些message按顺序添加到一个叫做commit log的文件中。每个partition中的 消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。
每个partition,都对应一个commit log文件。一个partition中的message的offset都是唯一的,但是不同的partition 中的message的offset可能是相同的。
kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间(log.retention.hours)确认消息多 久被删除,默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,因此保存大量的数据消息日 志信息不会有什么影响。
每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,消费offset由consumer自己来维护;一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息, 或者跳过某些消息。
这意味kafka中的consumer对集群的影响是非常小的,添加一个或者减少一个consumer,对于集群或者其他consumer 来说,都是没有影响的,因为每个consumer维护各自的消费offset。
理解Topic,Partition和Broker
一个topic,代表逻辑上的一个业务数据集,比如按数据库里不同表的数据操作消息区分放入不同topic,订单相关操作消 息放入订单topic,用户相关操作消息放入用户topic,对于大型网站来说,后端数据都是海量的,订单消息很可能是非常 巨量的,比如有几百个G甚至达到TB级别,如果把这么多数据都放在一台机器上可定会有容量限制问题,那么就可以在 topic内部划分多个partition来分片存储数据,不同的partition可以位于不同的机器上,每台机器上都运行一个Kafka的 进程Broker。
为什么要对Topic下数据进行分区存储?
1、commit log文件会受到所在机器的文件系统大小的限制,分区之后可以将不同的分区放在不同的机器上,相当于对 数据做了分布式存储,理论上一个topic可以处理任意数量的数据。
2、为了提高并行度
Producers
生产者将消息发送到topic中去,同时负责选择将message发送到topic的哪一个partition中。通过roundrobin做简单的 负载均衡。也可以根据消息中的某一个关键字来进行区分。通常第二种方式使用的更多。
Consumers
传统的消息传递模式有2种:队列( queue) 和(publish-subscribe)
queue模式:多个consumer从服务器中读取数据,消息只会到达一个consumer。
publish-subscribe模式:消息会被广播给所有的consumer。
Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group。
queue模式:所有的consumer都位于同一个consumer group 下。
publish-subscribe模式:所有的consumer都有着自己唯一的consumer group。
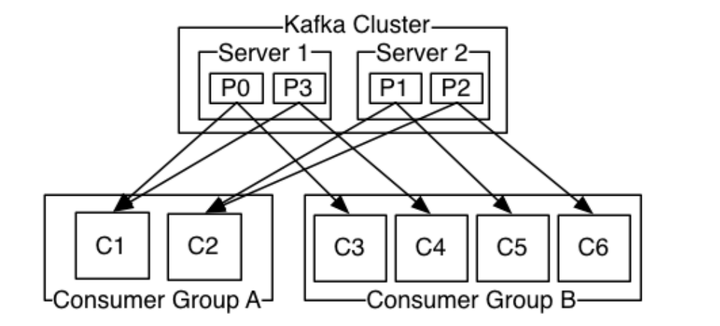
上图说明:由2个broker组成的kafka集群,某个主题总共有4个partition(P0-P3),分别位于不同的broker上。这个集群 由2个Consumer Group消费, A有2个consumer instances ,B有4个消费者实例。
通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者( logical subscriber )。每个consumer group由多个consumer instance组成,从而达到可扩展和容灾的功能。
消费顺序
**一个partition同一个时刻在一个consumer group中只能有一个consumer instance在消费,**从而保证消费顺序。 consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多,否则,多出来的 consumer消费不到消息。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序 性。
如果有在总体上保证消费顺序的需求,那么我们可以通过将topic的partition数量设置为1,将consumer group中的 consumer instance数量也设置为1,但是这样会影响性能,所以kafka的顺序消费很少用。
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06