
 HashMap 详解
HashMap 详解
# 简介
HashMap实现了Map接口,并继承 AbstractMap 抽象类,其中 Map 接口定义了键值映射规则。和 AbstractCollection抽象类在 Collection 族的作用类似, AbstractMap 抽象类提供了 Map 接口的骨干实现,以最大限度地减少实现Map接口所需的工作。
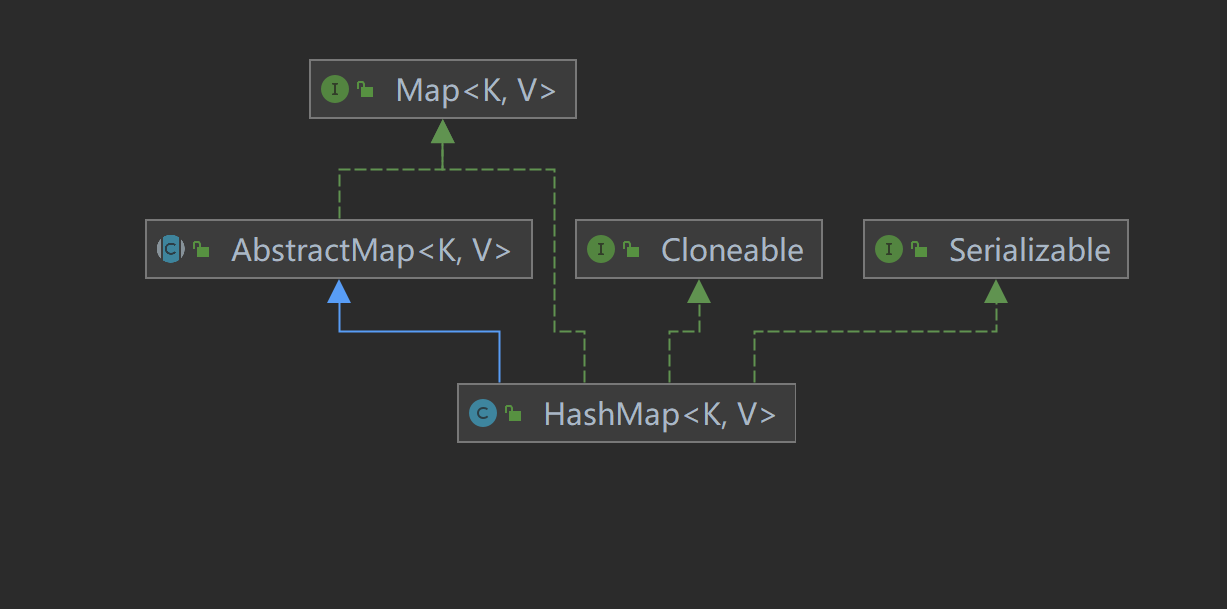
本文主要讲解 jdk 1.8 版本的实现。
# 底层实现
JDK 1.7 : Table数组+ Entry链表; JDK1.8 : Table数组+ Entry链表/红黑树
# JDK1.8 之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在⼀起使⽤也就是 链表散列。HashMap 通过key的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这⾥的 n 指的是数组的⻓度),如果当前位置存在元素的话,就判断该元素与要存⼊的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法, 换句话说使用扰动函数之后可以减少碰撞。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
# JDK 1.8之后
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
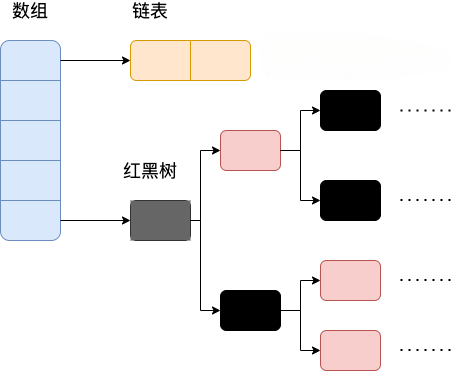
# 哈希的相关概念
Hash 就是把任意长度的输入(又叫做预映射, pre-image),通过哈希算法,变换成固定长度的输出(通常是整型),该输出就是哈希值。这种转换是一种 压缩映射 ,也就是说,散列值的空间通常远小于输入的空间。不同的输入可能会散列成相同的输出,从而不可能从散列值来唯一的确定输入值。简单的说,就是一种将任意长度的消息压缩到某一固定长度的息摘要函数。
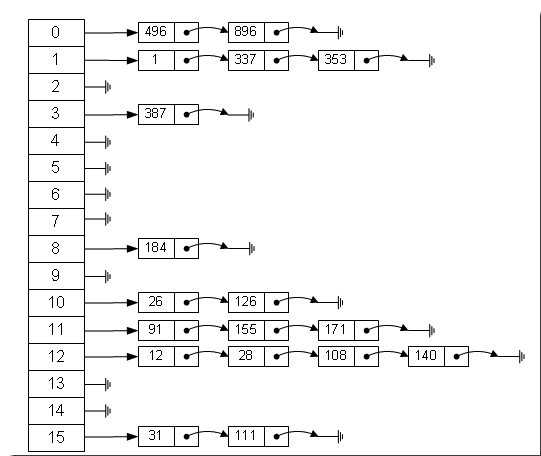
# 解决hash冲突的办法有哪些?HashMap用的哪种?
解决Hash冲突方法有:开放定址法、再哈希法、链地址法。HashMap中采用的是 链地址法 。
- 开放定址法基本思想就是,如果
p=H(key)出现冲突时,则以p为基础,再次hash,p1=H(p),如果p1再次出现冲突,则以p1为基础,以此类推,直到找到一个不冲突的哈希地址pi。 因此开放定址法所需要的hash表的长度要大于等于所需要存放的元素,而且因为存在再次hash,所以只能在删除的节点上做标记,而不能真正删除节点。 - 再哈希法提供多个不同的hash函数,当
R1=H1(key1)发生冲突时,再计算R2=H2(key1),直到没有冲突为止。 这样做虽然不易产生堆集,但增加了计算的时间。 - 链地址法将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
# JDK 1.8 hash方法源码
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:⽆符号右移,忽略符号位,空位都以0补⻬
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2
3
4
5
6
7
8
9
10
11
这是1.7的hash方法
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
2
3
4
5
6
7
# HashMap数据结构
每一个节点是Node<K,V>表示
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
2
3
4
5
6
Node是一个内部类,这里的key为键,value为值,next指向下一个元素,可以看出HashMap中的元素不是一个单纯的键值对,还包含下一个元素的引用(链表时使用)。
数据结构是数组 + 链表或者红黑树
当hash冲突时候,以链表形式存在,如果链表长度大于8并且数组长度大于64时,转换成红黑树,长度小于6时再转换成链表。
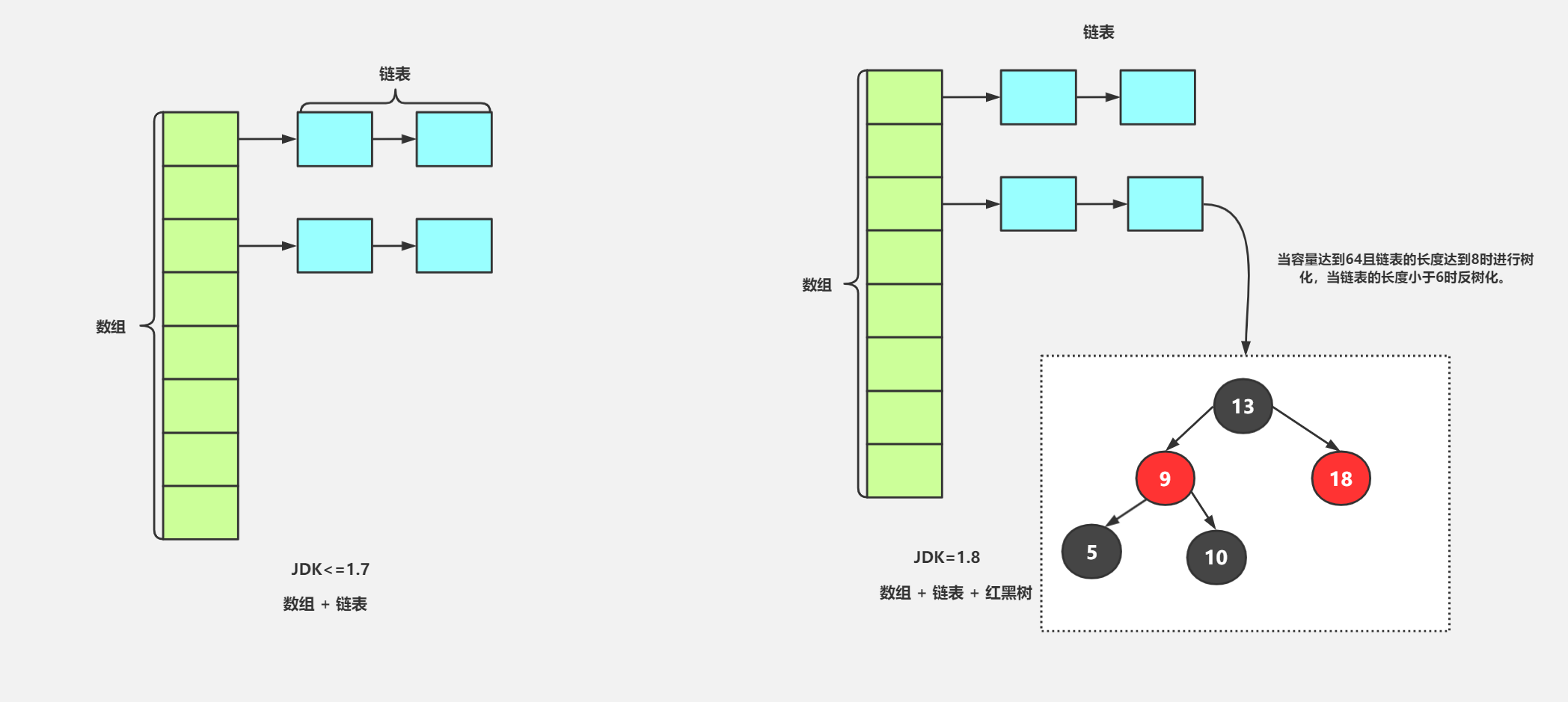
# 存储元素过程
1、计算出key的hash值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2
3
4
2、初始化数组长度
默认数组长度是16,加载因子是0.7
用数组容量大小乘以加载因子得到一个值,一旦数组中存储的元素个数超过该值就会调用rehash方法将数组容量增加到原来的两倍,专业术语叫做扩容.
在做扩容的时候会生成一个新的数组,原来的所有数据需要重新计算哈希码值重新分配到新的数组,所以扩容的操作非常消耗性能.
3、计算元素数组中下标
(n - 1) & hash
n是数组长度
分为两种情况:
- 当前位置没有元素直接把node节点放进去
tab[i] = newNode(hash, key, value, null);
- 当前位置有元素
如果key值相同,直接替换;不相同以链表或者红黑树存在
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//判断key是不是完全相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//遍历链表
for (int binCount = 0; ; ++binCount) {
//找到链表的尾节点
if ((e = p.next) == null) {
//插入到链表尾节点
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//key 相同时候替换旧值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
简单来说,put流程是:
1、如果table没有初始化就先进行初始化过程
2、使用hash算法计算key的索引
3、判断索引处有没有存在元素,没有就直接插入
4、如果索引处存在元素,则遍历插入,有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入
5、链表的数量大于阈值8,就要转换成红黑树的结构
6、添加成功后会检查是否需要扩容
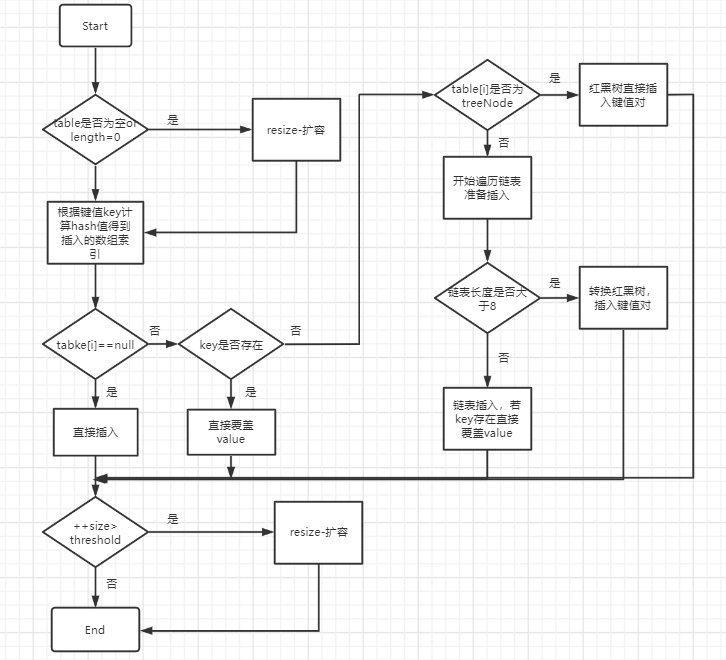
为什么要转换成红黑树?
为链表中元素太多的时候会影响查找效率,所以当链表的元素个数达到8的时候使用链表存储就转变成了使用红黑树存储,原因就是红黑树是平衡二叉树,在查找性能方面比链表要高.
# 查找元素过程
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//从红黑树中查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//循环链表中查找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 为什么建议设置HashMap的容量?
HashMap有扩容机制,就是当达到扩容条件时会进行扩容。扩容条件就是当HashMap中的元素个数超过临界值时就会自动扩容(threshold = loadFactor * capacity)。
如果我们没有设置初始容量大小,随着元素的不断增加,HashMap会发生多次扩容。而HashMap每次扩容都需要重建hash表,非常影响性能。所以建议开发者在创建HashMap的时候指定初始化容量。
# HashMap 的长度为什么是2的次幂
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。Hash 值的范围值-2147483648到2147483647,前后加起来⼤概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度度取模运算,得到的余数才能⽤来要存放的位置也就是对应的数组下标。这个数组下标的计算⽅法是 (n - 1) &hash 。(n代表数组长度)
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。” 并且采用二进制位操作 &,相对于%能够提⾼运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。
# HashMap 多线程操作导致死循环问题
JDK1.7 及之前版本的 HashMap 在多线程环境下扩容操作可能存在死循环问题,这是由于当一个桶位中有多个元素需要进行扩容时,多个线程同时对链表进行操作,头插法可能会导致链表中的节点指向错误的位置,从而形成一个环形链表,进而使得查询元素的操作陷入死循环无法结束。
为了解决这个问题,JDK1.8 版本的 HashMap 采用了尾插法而不是头插法来避免链表倒置,使得插入的节点永远都是放在链表的末尾,避免了链表中的环形结构。但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在数据覆盖的问题。并发环境下,推荐使用 ConcurrentHashMap 。
# 新的Entry节点在插入链表的时候,是怎么插入的?
java8之前是头插法,就是说新来的值会取代原有的值,原有的值就顺推到链表中去。
我们现在往一个容量大小为2的put两个值,负载因子是0.75是不是我们在put第二个的时候就会进行resize?
2*0.75 = 1 所以插入第二个就要resize了。
现在我们要在容量为2的容器里面用不同线程插入A,B,C,假如我们在resize之前打个断点,那意味着数据都插入了但是还没resize那扩容前可能是这样的。
我们可以看到链表的指向A->B->C
注意:A的下一个指针是指向B的
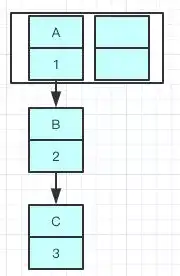
因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
就可能出现下面的情况,大家发现问题没有?
B的下一个指针指向了A
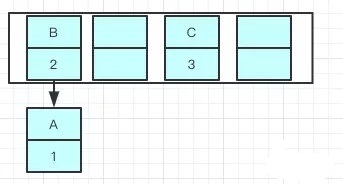
一旦几个线程都调整完成,就可能出现环形链表

如果这个时候去取值,出现了——Infinite Loop。
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B
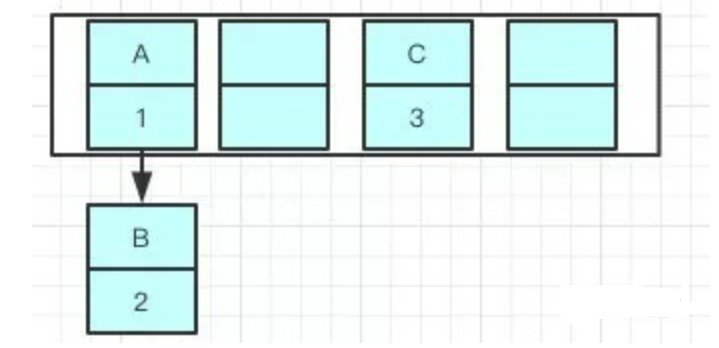
jdk 1.7 在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。Java 8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
# HashMap 常见的遍历方式
HashMap 遍历从大的方向来说,可分为以下 4 类:
- 迭代器(Iterator)方式遍历;
- For Each 方式遍历;
- Lambda 表达式遍历(JDK 1.8+);
- Streams API 遍历(JDK 1.8+)。
但每种类型下又有不同的实现方式,因此具体的遍历方式又可以分为以下 7 种:
- 使用迭代器(Iterator)EntrySet 的方式进行遍历;
- 使用迭代器(Iterator)KeySet 的方式进行遍历;
- 使用 For Each EntrySet 的方式进行遍历;
- 使用 For Each KeySet 的方式进行遍历;
- 使用 Lambda 表达式的方式进行遍历;
- 使用 Streams API 单线程的方式进行遍历;
- 使用 Streams API 多线程的方式进行遍历。
# 迭代器 EntrySet
public static void main(String[] args) {
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "Python");
map.put(3, "Go");
map.put(4, "C");
map.put(5, "C++");
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 迭代器 KeySet
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer key = iterator.next();
System.out.println(key);
System.out.println(map.get(key));
}
2
3
4
5
6
# ForEach EntrySet
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
2
3
4
# ForEach KeySet
for (Integer key : map.keySet()) {
System.out.println(key);
System.out.println(map.get(key));
}
2
3
4
# Lambda
map.forEach((key, value) -> {
System.out.println(key);
System.out.println(value);
});
2
3
4
# Stream API 单线程
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
2
3
4
# Stream API 多线程
map.entrySet().parallelStream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
2
3
4
# 性能比较
我们使用 Oracle 官方提供的性能测试工具 JMH(Java Microbenchmark Harness,JAVA 微基准测试套件)来测试一下这 7 种循环的性能。
首先,我们先要引入 JMH 框架,在 pom.xml 文件中添加如下配置:
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-core -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.23</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-generator-annprocess -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.23</version>
<scope>provided</scope>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.AverageTime) // 测试完成时间
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 2, time = 1, timeUnit = TimeUnit.SECONDS) // 预热 2 轮,每次 1s
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS) // 测试 5 轮,每次 1s
@Fork(1) // fork 1 个线程
@State(Scope.Thread) // 每个测试线程一个实例
public class HashMapCycleTest {
static Map<Integer, String> map = new HashMap() {{
// 添加数据
for (int i = 0; i < 100; i++) {
put(i, "val:" + i);
}
}};
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(HashMapCycleTest.class.getSimpleName()) // 要导入的测试类
.output("C:\\Users\\admin\\Downloads\\jmh-map.log") // 输出测试结果的文件
.build();
new Runner(opt).run(); // 执行测试
}
@Benchmark
public void entrySet() {
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
Integer k = entry.getKey();
String v = entry.getValue();
}
}
@Benchmark
public void forEachEntrySet() {
// 遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
Integer k = entry.getKey();
String v = entry.getValue();
}
}
@Benchmark
public void keySet() {
// 遍历
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer k = iterator.next();
String v = map.get(k);
}
}
@Benchmark
public void forEachKeySet() {
// 遍历
for (Integer key : map.keySet()) {
Integer k = key;
String v = map.get(k);
}
}
@Benchmark
public void lambda() {
// 遍历
map.forEach((key, value) -> {
Integer k = key;
String v = value;
});
}
@Benchmark
public void streamApi() {
// 单线程遍历
map.entrySet().stream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
}
@Benchmark
public void parallelStreamApi() {
// 多线程遍历
map.entrySet().parallelStream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
测试结果如下:
Benchmark Mode Cnt Score Error Units
HashMapCycleTest.entrySet avgt 5 222.049 ± 5.067 ns/op
HashMapCycleTest.forEachEntrySet avgt 5 221.174 ± 4.882 ns/op
HashMapCycleTest.forEachKeySet avgt 5 330.700 ± 15.932 ns/op
HashMapCycleTest.keySet avgt 5 345.960 ± 19.577 ns/op
HashMapCycleTest.lambda avgt 5 162.708 ± 7.466 ns/op
HashMapCycleTest.parallelStreamApi avgt 5 9007.014 ± 782.653 ns/op
HashMapCycleTest.streamApi avgt 5 247.204 ± 5.463 ns/op
2
3
4
5
6
7
8
其中 Units 为 ns/op 意思是执行完成时间(单位为纳秒),而 Score 列为平均执行时间, ± 符号表示误差。
parallelStream这种方式比较特殊,如果每次循环的时候sleep(5),parallelStream是最快的,我们看下测试结果:
Benchmark Mode Cnt Score Error Units
HashMapCycleTest.entrySet avgt 5 535831120.000 ± 11197963.718 ns/op
HashMapCycleTest.forEachEntrySet avgt 5 540130170.000 ± 10385414.215 ns/op
HashMapCycleTest.forEachKeySet avgt 5 540394920.000 ± 12432449.152 ns/op
HashMapCycleTest.keySet avgt 5 538228430.000 ± 5200538.597 ns/op
HashMapCycleTest.lambda avgt 5 540790870.000 ± 7409835.497 ns/op
HashMapCycleTest.parallelStreamApi avgt 5 43272752.500 ± 931860.738 ns/op
HashMapCycleTest.streamApi avgt 5 541333710.000 ± 13100356.686 ns/op
2
3
4
5
6
7
8
再没有sleep情况下, entrySet 的性能比 keySet 的性能高出了一倍之多,在有sleep情况 parallelStream 是最快的。
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06