
 kafka基本使用
kafka基本使用
# 安装kafka
# 安装zookeeper
kafka依赖zookeeper,需要先安装zookeeper
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.8/apache-zookeeper-3.5.8-bin.tar.gz
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
cd apache-zookeeper-3.5.8-bin
cp conf/zoo_sample.cfg conf/zoo.cfg
# 启动zookeeper
bin/zkServer.sh start
bin/zkCli.sh
2
3
4
5
6
7
8
# 下载安装包
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.11-2.4.1.tgz
tar -xzf kafka_2.11-2.4.1.tgz
cd kafka_2.11-2.4.1
2
3
# 修改配置
修改配置文件config/server.properties:
#broker.id属性在kafka集群中必须要是唯一
broker.id=0
#kafka部署的机器ip和提供服务的端口号
listeners=PLAINTEXT://ip:9092
#kafka的消息存储文件
log.dir=/usr/local/data/kafka-logs
#kafka连接zookeeper的地址
zookeeper.connect=ip:2181
2
3
4
5
6
7
8
# 启动服务
#-daemon表示以后台进程运行
kafka-server-start.sh [-daemon] server.properties
#或者用
bin/kafka-server-start.sh config/server.properties &
2
3
4
5
server.properties核心配置详解:
| Property | Default | Description |
|---|---|---|
| broker.id | 0 | 每个broker都可以用一个唯一的非负整数id进行标识;这个id可以作为broker的“名字”,你可以选择任意你喜欢的数字作为id,只要id是唯一的即可。 |
| log.dirs | /tmp/kafka-logs | kafka存放数据的路径。这个路径并不是唯一的,可以是多个,路径之间只需要使用逗号分隔即可;每当创建新partition时,都会选择在包含最少partitions的路径下进行。 |
| listeners | PLAINTEXT://192.168.123.10:9092 | server接受客户端连接的端口,ip配置kafka本机ip即可 |
| zookeeper.connect | localhost:2181 | zooKeeper连接字符串的格式为:hostname:port,此处hostname和port分别是ZooKeeper集群中某个节点的host和port;zookeeper如果是集群,连接方式为 hostname1:port1, hostname2:port2, hostname3:port3 |
| log.retention.hours | 168 | 每个日志文件删除之前保存的时间。默认数据保存时间对所有topic都一样。 |
| num.partitions | 1 | 创建topic的默认分区数 |
| default.replication.factor | 1 | 自动创建topic的默认副本数量,建议设置为大于等于2 |
| min.insync.replicas | 1 | 当producer设置acks为-1时,min.insync.replicas指定replicas的最小数目(必须确认每一个repica的写数据都是成功的),如果这个数目没有达到,producer发送消息会产生异常 |
| delete.topic.enable | false | 是否允许删除主题 |
# kafka的两个配置listeners和advertised.listeners
# listeners:
kafka监听的网卡的ip,假设你机器上有两张网卡,内网192.168.0.213和外网101.89.163.1 如下配置
#kafka只监听内网网卡,即只接收内网网卡的数据
listeners=PLAINTEXT://192.168.0.213:9092
#kafka只监听外网网卡,即只接收外网网卡的数据
listeners=PLAINTEXT://101.89.163.1:9092
2
3
4
5
# advertised.listeners
listeners=PLAINTEXT://192.168.0.213:9092
advertised.listeners=PLAINTEXT://101.89.163.1:9092
2
kafka 节点启动后,会向 zookeeper 注册自己,同时告诉 zookeeper 自身的通信地址,这个地址就是配置文件中的 advertised.listeners,如果没有配置 advertised.listeners,就会使用listeners。同时从 zookeeper 中获取兄弟节点的这个地址,以便与兄弟节点通信。即 kafka 节点是从 zookeeper 获取的其他节点的通信地址。 我们使用客户端以一个 ip 地址首次连接 kafka 节点后,节点返回给客户端的 kafka 集群地址就是从 zookeeper 中获得的这些地址,也就是各个节点配置的 advertised.listeners,包括当前连接的节点。所以可能客户端后续访问当前节点的 ip 地址有可能和首次连接的 ip 地址并不一样。
# 创建主题
现在我们来创建一个名字为“test”的Topic,这个topic只有一个partition,并且备份因子也设置为1:
bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic test
创建多个分区的主题:
bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 2 --topic test1
# 发送消息
kafka自带了一个producer命令客户端
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test
# 消费消息
kafka默认有一个命令行客户端,会将获取到内容在命令中进行输出,默认是消费最新的消息:
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test
指定消费组
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --consumer-property group.id=testGroup --topic test
同一条消息只能被同一个消费组下的某一个消费者消费,要实现多播只要保证这些消费者属于不同的消费组即可。
# kafka集群实战
多个kafka节点组成kafka集群。本次演示同一台机器安装3个实例。
建立另外2个broker的配置文件:
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
2
config/server-1.properties:
#broker.id属性在kafka集群中必须要是唯一
broker.id=1
#kafka部署的机器ip和提供服务的端口号
listeners=PLAINTEXT://192.168.123.10:9093
log.dir=/usr/local/data/kafka-logs-1
#kafka连接zookeeper的地址,要把多个kafka实例组成集群,对应连接的zookeeper必须相同
zookeeper.connect=127.0.0.1:2181
2
3
4
5
6
7
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://192.168.123.10:9094
log.dir=/usr/local/data/kafka-logs-2
zookeeper.connect=127.0.0.1:2181
2
3
4
启动2个broker实例即可:
bin/kafka-server-start.sh -daemon config/server-1.properties
bin/kafka-server-start.sh -daemon config/server-2.properties
2
# 副本的ACK机制
producer是不断地往Kafka中写入数据,写入数据会有一个返回结果,表示是否写入成功。这里对应有一个ACKs的配置。
acks = 0:生产者只管写入,不管是否写入成功,可能会数据丢失。性能是最好的
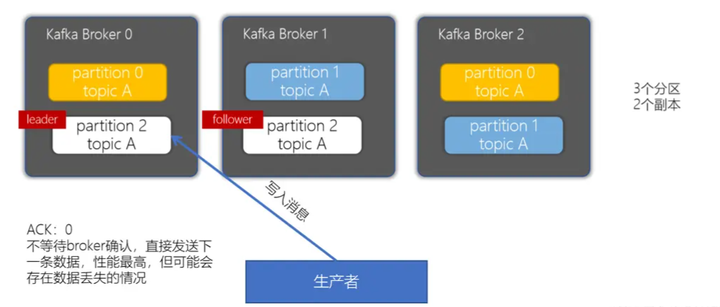
acks = 1:生产者会等到leader分区写入成功后,返回成功,接着发送下一条
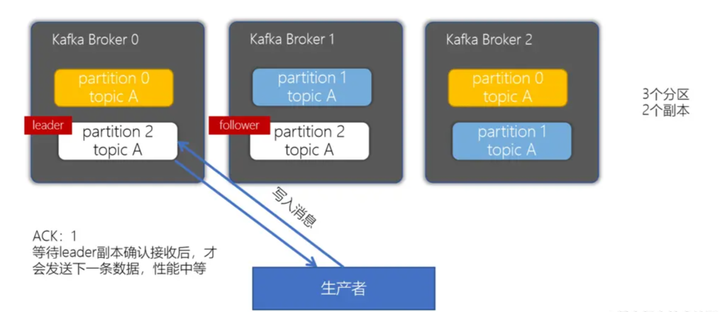
acks = -1/all:确保消息写入到leader分区、还确保消息写入到对应副本都成功后,接着发送下一条,性能是最差的
# Spring Boot整合Kafka
引入spring boot kafka依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2
3
4
application.yml配置:
server:
port: 8080
spring:
kafka:
bootstrap-servers: 8.140.246.47:9092
producer: # 生产者
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384
buffer-memory: 33554432
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
retry.backoff.ms: 100 #重试时间间隔,默认100
linger.ms: 0 #默认为0,表示批量发送消息之前等待更多消息加入batch的时间
max.request.size: 1048576 #默认1MB,表示发送消息最大值
connections.max.idle.ms: 540000 #默认9分钟,表示多久后关闭限制的连接
receive.buffer.bytes: 32768 #默认32KB,表示socket接收消息缓冲区的大小,为-1时使用操作系统默认值
send.buffer.bytes: 131072 #默认128KB,表示socket发送消息缓冲区大小,为-1时使用操作系统默认值
# request.timeout.ms: 10000 #默认30000ms,表示等待请求响应的最长时间
# max.block.ms: 1000
consumer:
auto-commit-interval: 5000 #自动提交消费位移时间隔时间
max-poll-records: 500 #批量消费每次最多消费多少条消息
client-id: kafka.consumer.client.id #消费者客户端ID
group-id: default-group
enable-auto-commit: false
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
fetch-max-wait: 400 #最大等待时间
fetch-min-size: 1 #最小消费字节数
heartbeat-interval: 3000 #分组管理时心跳到消费者协调器之间的预计时间
isolation-level: read_committed
listener:
# 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
# RECORD
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# BATCH
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
# TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# COUNT
# TIME | COUNT 有一个条件满足时提交
# COUNT_TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
# MANUAL
# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
# MANUAL_IMMEDIATE
ack-mode: manual_immediate
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
生产者代码:
package com.demo.service;
import lombok.RequiredArgsConstructor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.messaging.Message;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import java.util.concurrent.ExecutionException;
@Service
@RequiredArgsConstructor
public class ProducerServiceImpl {
private final KafkaTemplate<String, String> kafkaTemplate;
private static final Logger logger = LoggerFactory.getLogger(ProducerServiceImpl.class);
public void sendSyncMessage(String topic, String data) throws ExecutionException, InterruptedException {
SendResult<String, String> sendResult = kafkaTemplate.send(topic, data).get();
RecordMetadata recordMetadata = sendResult.getRecordMetadata();
logger.info("发送同步消息成功!发送的主题为:{}", recordMetadata.topic());
}
public void sendMessage(String topic, String data) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, data);
future.addCallback(success -> logger.info("发送消息成功!"), failure -> logger.error("发送消息失败!失败原因是:{}", failure.getMessage()));
}
public void sendMessage(ProducerRecord<String, String> record) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(record);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
logger.error("发送消息失败!失败原因是:{}", throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> sendResult) {
RecordMetadata metadata = sendResult.getRecordMetadata();
logger.info("发送消息成功!消息主题是:{},消息分区是:{}", metadata.topic(), metadata.partition());
}
});
}
public void sendMessage(Message<String> message) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(message);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
logger.error("发送消息失败!失败原因是:{}", throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> sendResult) {
RecordMetadata metadata = sendResult.getRecordMetadata();
logger.info("发送消息成功!消息主题是:{},消息分区是:{}", metadata.topic(), metadata.partition());
}
});
}
public void sendMessage(String topic, String key, String data) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, key, data);
future.addCallback(success -> logger.info("发送消息成功!"), failure -> logger.error("发送消息失败!失败原因是:{}", failure.getMessage()));
}
public void sendMessage(String topic, Integer partition, String key, String data) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, partition, key, data);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
logger.error("发送消息失败!失败原因是:{}", throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> sendResult) {
RecordMetadata metadata = sendResult.getRecordMetadata();
logger.info("发送消息成功!消息主题是:{},消息分区是:{}", metadata.topic(), metadata.partition());
}
});
}
public void sendMessage(String topic, Integer partition, Long timestamp, String key, String data) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, partition, timestamp, key, data);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
logger.error("发送消息失败!失败原因是:{}", throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> sendResult) {
RecordMetadata metadata = sendResult.getRecordMetadata();
logger.info("发送消息成功!消息主题是:{},消息分区是:{}", metadata.topic(), metadata.partition());
}
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
消费者代码:
@Component
public class MyConsumer {
/**
* @KafkaListener(groupId = "testGroup", topicPartitions = {
* @TopicPartition(topic = "topic1", partitions = {"0", "1"}),
* @TopicPartition(topic = "topic2", partitions = "0",
* partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100"))
* },concurrency = "6")
* //concurrency就是同组下的消费者个数,就是并发消费数,必须小于等于分区总数
* @param record
*/
@KafkaListener(topics = "my-replicated-topic",groupId = "costomGroup")
public void listen(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
//手动提交offset
ack.acknowledge();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 分区策略
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中:
# 1. 轮询分区策略
即按消息顺序进行分区顺序分配,是默认的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区;
key为null,则使用轮询算法均衡地分配分区;
# 2. 按key分区分配策略
key不为null,key.hash() % n
但是按照key决定分区有可能会造成数据倾斜
# 3. 随机分区策略
随机分区,不建议使用
# 4. 自定义分区策略
根据业务需要制定以分区策略
# 消费者分区策略
同一时刻,一条消息只能被组中的一个消费者实例消费:
- 消费者数=分区数:一个分区对应一个消费者
- 消费者数<分区数:一个消费者对应多个分区
- 消费者数>分区数:多出来的消费者将不会消费任何消息
分区分配策略:保障每个消费者尽量能够均衡地消费分区的数据,不能出现某个消费者消费分区的数量特别多,某个消费者消费的分区特别少
1. Range分配策略(范围分配策略):Kafka默认的分配策略
计算公式:
n=分区数量/消费者数量
m=分区数量%消费者数量
前m个消费者消费n+1个,剩余消费者消费n个
以上图为例:n=8/3=2m=8%3=2因此前2个消费者消费2+1=3个分区,剩下1个消费者消费2个分区
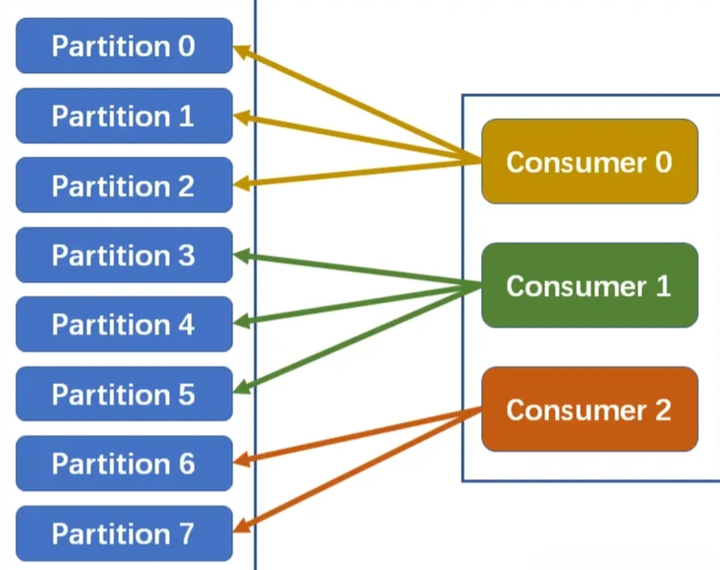
2. RoundRobin分配策略(轮询分配策略)
消费者挨个分配消费的分区:
如下图,3个消费者共同消费8个分区
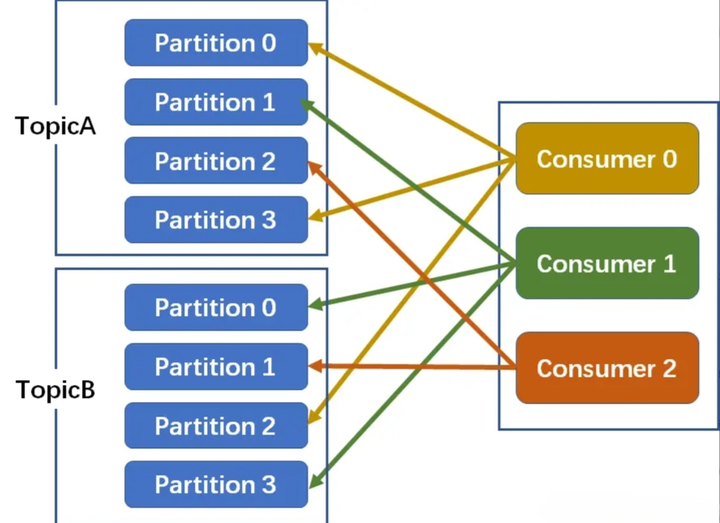
第一轮:Consumer0-->A-Partition0;Consumer1-->A-Partition1;Consumer2-->A-Partition2
第二轮:Consumer0-->A-Partition3;Consumer1-->B-Partition0;Consumer2-->B-Partition1
第三轮:Consumer0-->B-Partition2;Consumer1-->B-Partition3
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06