
 Redis hot key 发现以及解决办法
Redis hot key 发现以及解决办法
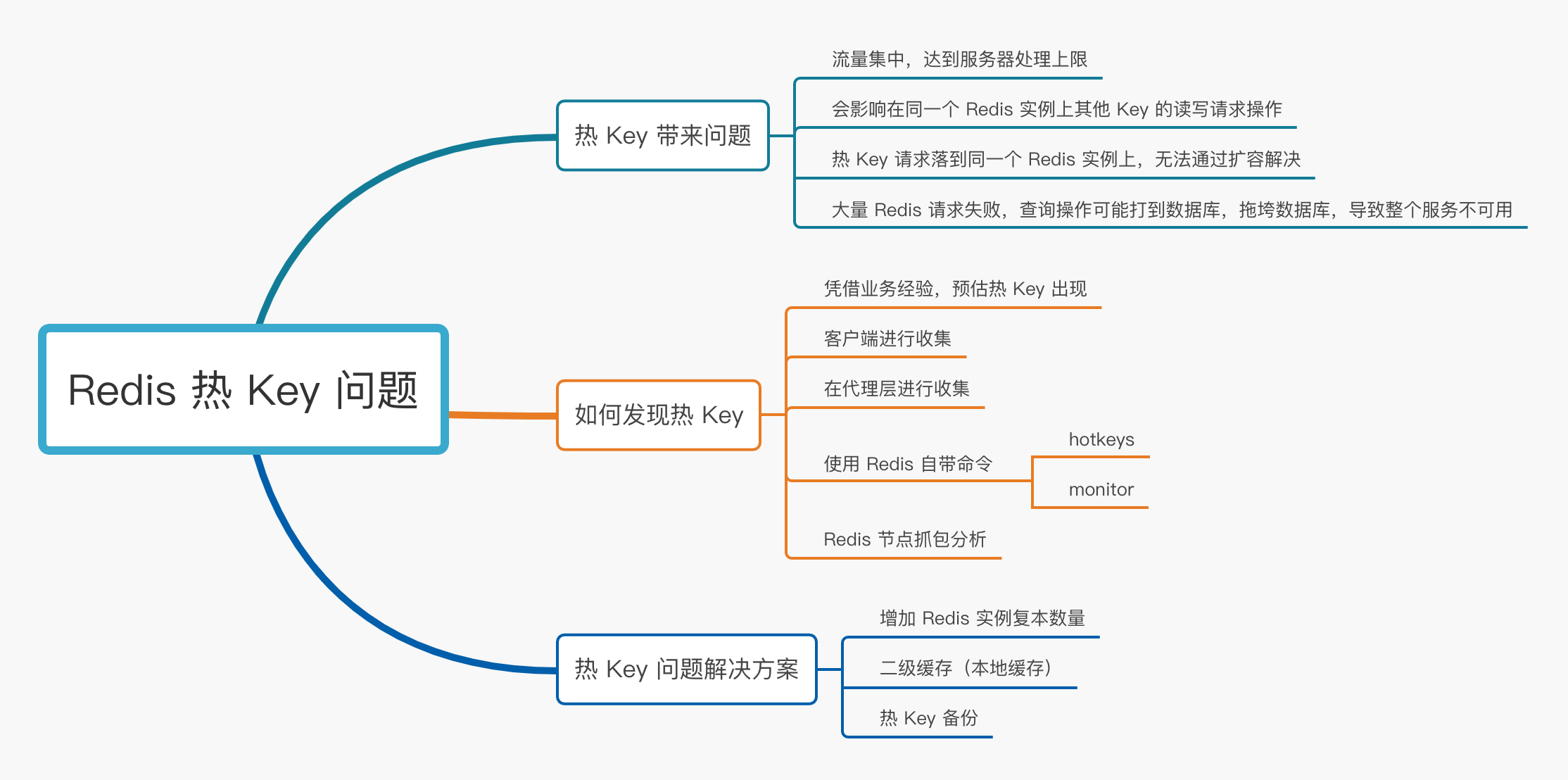
# 热 Key 带来问题
所谓热key问题就是,突然有几十万的请求去访问redis上的某个特定key。那么,这样会造成流量过于集中,达到物理网卡上限,从而导致这台redis的服务器宕机。
由于某个 Key 的数据一定是存储到后端某台服务器的 Redis 单个实例上,如果对这个 Key 突然出现大量的请求操作,这样就会造成流量过于集中,达到 Redis 单个实例处理上限,可能会导致 Redis 实例 CPU 使用率 100%,或者是网卡流量达到上限等,对系统的稳定性和可用性造成影响,或者更为严重出现服务器宕机,无法对外提供服务;更有甚者在出现 Redis 服务不可用之后,大量的数据请求全部落地数据库查询上,Redis 都已经顶不住了,数据库也是分分钟挂掉的节奏。
- 流量集中,达到服务器处理上限(
CPU、网络IO等); - 会影响在同一个
Redis实例上其他Key的读写请求操作; - 热
Key请求落到同一个Redis实例上,无法通过扩容解决; - 大量
Redis请求失败,查询操作可能打到数据库,拖垮数据库,导致整个服务不可用。
# 如何发现热 Key
# 凭借业务经验,预估热 Key 出现
根据业务系统上线的一些活动和功能,我们是可以在某些场景下提前预估热 Key 的出现的,比如业务需要进行一场商品秒杀活动,秒杀商品信息和数量一般都会缓存到 Redis 中,这种场景极有可能出现热 Key 问题的。
- 优点:简单,凭经验发现热
Key,提早发现提早处理; - 缺点:没有办法预测所有热
Key出现,比如某些热点新闻事件,无法提前预测。
# 客户端进行收集
一般我们在连接 Redis 服务器时都要使用专门的 SDK(比如:Java 的客户端工具 Jedis、Redisson),我们可以对客户端工具进行封装,在发送请求前进行收集采集,同时定时把收集到的数据上报到统一的服务进行聚合计算。
- 优点:方案简单
- 缺点:
- 对客户端代码有一定入侵,或者需要对
SDK工具进行二次开发; - 没法适应多语言架构,每一种语言的
SDK都需要进行开发,后期开发维护成本较高。
- 对客户端代码有一定入侵,或者需要对
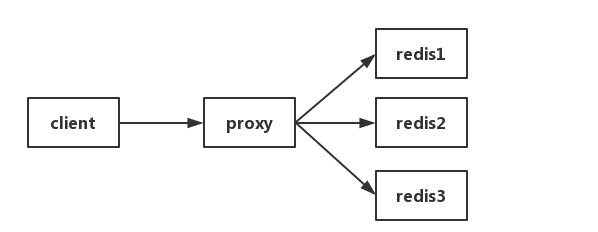
# 在代理层进行收集
如果所有的 Redis 请求都经过 Proxy(代理)的话,可以考虑改动 Proxy 代码进行收集,思路与客户端基本类似。
hotkeys 参数
Redis 在 4.0.3 版本中添加了 hotkeys (opens new window) 查找特性,可以直接利用 redis-cli --hotkeys 获取当前 keyspace 的热点 key,实现上是通过 scan + object freq 完成的。
monitor 命令可以实时抓取出 Redis 服务器接收到的命令,通过 redis-cli monitor 抓取数据,同时结合一些现成的分析工具,比如 redis-faina (opens new window),统计出热 Key。
# Redis 节点抓包分析
Redis 客户端使用 TCP 协议与服务端进行交互,通信协议采用的是 RESP 协议。自己写程序监听端口,按照 RESP 协议规则解析数据,进行分析。或者我们可以使用一些抓包工具,比如 tcpdump 工具,抓取一段时间内的流量进行解析。
# 热 Key 问题解决方案
# 增加 Redis 实例复本数量
对于出现热 Key 的 Redis 实例,我们可以通过水平扩容增加副本数量,将读请求的压力分担到不同副本节点上。
# 二级缓存(本地缓存)
当出现热 Key 以后,把热 Key 加载到系统的 JVM 中。后续针对这些热 Key 的请求,会直接从 JVM 中获取,而不会走到 Redis 层。这些本地缓存的工具很多,比如 Ehcache,或者 Google Guava 中 Cache 工具,或者直接使用 HashMap 作为本地缓存工具都是可以的。
使用本地缓存需要注意两个问题:
- 如果对热
Key进行本地缓存,需要防止本地缓存过大,影响系统性能; - 需要处理本地缓存和
Redis集群数据的一致性问题。
# 热 Key 备份
通过前面的分析,我们可以了解到,之所以出现热 Key,是因为有大量的对同一个 Key 的请求落到同一个 Redis 实例上,如果我们可以有办法将这些请求打散到不同的实例上,防止出现流量倾斜的情况,那么热 Key 问题也就不存在了。
那么如何将对某个热 Key 的请求打散到不同实例上呢?我们就可以通过热 Key 备份的方式,基本的思路就是,我们可以给热 Key 加上前缀或者后缀,把一个热 Key 的数量变成 Redis 实例个数 N 的倍数 M,从而由访问一个 Redis Key 变成访问 N * M 个 Redis Key。 N * M 个 Redis Key 经过分片分布到不同的实例上,将访问量均摊到所有实例。

在这段代码中,通过一个大于等于 1 小于 M 的随机数,得到一个 bakHotKey,程序会优先访问 bakHotKey,在得不到数据的情况下,再访问原来的 hotkey,并将 hotkey 的内容写回 bakHotKey。值得注意的是,bakHotKey 的过期时间是 hotkey 的过期时间加上一个较小的随机正整数,这是通过坡度过期的方式,保证在 hotkey 过期时,所有 bakHotKey 不会同时过期而造成缓存雪崩。
使用京东框架发现热key,https://gitee.com/jd-platform-opensource/hotkey
# 总结
在这一篇文章中我们首先分析了在 Redis 中热 Key 带来的一些问题,同时也介绍了在海量的 Redis Key 中找到热 Key 的一些方法,最后也提到了在解决热 Key 问题中我们常用的一些办法;总结来说,Redis 热 Key 问题首先是请求流量过大造成的,但是更深层次原因还是出现了流量倾斜,单个 Redis 实例承担的流量过大造成的,了解到了本质原因,解决的思路也就简单了,就是要想尽一切办法将单个实例承担的流量打散,让每个机器均衡承担热 Key 的流量,不要出现流量倾斜,保证系统的稳定性。
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06