
 Java 并发容器有哪些?
Java 并发容器有哪些?
# 一、写时复制容器
CopyOnWriteArrayList 和 CopyOnWriteArraySet CopyOnWrite 容器即写时复制的容器。是线程安全的容器
什么是线程安全?
当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些线程将如何交替执行,并且在调用代码中不需要任何额外的同步或者协同,这个类都能表现出正确的行为,那么就称这个类是线程安全的。

通俗的理解是当我们往一个容器添加 元素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一 个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指 向新的容器。
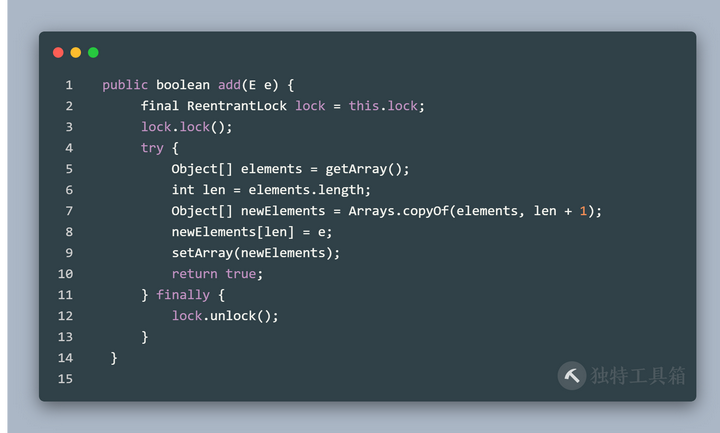
这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读,而不需要加锁, 因为当前容器不会添加任何元素。所以 CopyOnWrite 容器也是一种读写分离的思 想,读和写不同的容器。如果读的时候有多个线程正在向 CopyOnWriteArrayList 添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的 CopyOnWriteArrayList。
CopyOnWrite 并发容器用于对于绝大部分访问都是读,且只是偶尔写的并发 场景。比如白名单,黑名单,商品类目的访问和更新场景,假如我们有一个搜索 网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允 许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单每天晚上 更新一次。当用户搜索时,会检查当前关键字在不在黑名单当中,如果在,则提 示不能搜索。
使用 CopyOnWriteMap 需要注意两件事情:
减少扩容开销。根据实际需要,初始化 CopyOnWriteMap 的大小, 避免写时 CopyOnWriteMap 扩容的开销。
使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加 次数,可以减少容器的复制次数。
# 写时复制容器的问题
# 性能问题
每次修改都创建一个新数组,然后复制所有内容,如果数组比较大,修改操 作又比较频繁,可以想象,性能是很低的,而且内存开销会很大。
# 数据一致性问题。
CopyOnWrite 容器只能保证数据的最终一致性,不能保证数据的实时一致性。 所以如果你希望写入的的数据,马上能读到,不要使用 CopyOnWrite 容器。
适用场景:读多写少
# 二、ConcurrentHashMap
原理参见这个文章
# 三、ConcurrentSkipList 系列
ConcurrentSkipListMap 有序 Map
ConcurrentSkipListSet 有序 Set
TreeMap 和 TreeSet 使用红黑树按照 key 的顺序(自然顺序、自定义顺序) 来使得键值对有序存储*,*但是只能在单线程下安全使用;多线程下想要使键值对 按照 key 的顺序来存储,则需要使用 ConcurrentSkipListMap 和 ConcurrentSkipListSet,分别用以代替 TreeMap 和 TreeSet,存入的数据按 key 排 序。在实现上,ConcurrentSkipListSet 本质上就是 ConcurrentSkipListMap。ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表。

什么是跳表
传统意义的单链表是一个线性结构,向有序的链表中插入一个节点需要 O(n) 的时间,查找操作需要 O(n)的时间。
那我们有没有什么办法来提高查询的效率呢?我们可以为链表建立一个“索引”,这样查找起来就会更快,如下图所示,我们在原始链表的基础上,每两个结点提取一个结点建立索引,我们把抽取出来的结点叫做索引层或者索引,down 表示指向原始链表结点的指针。
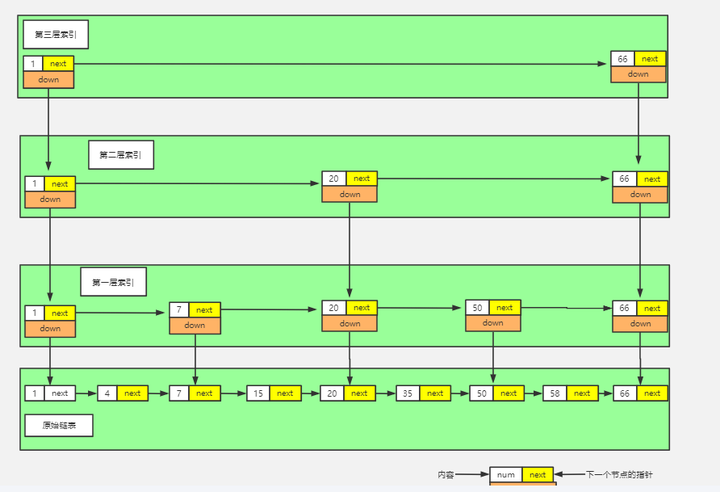
假如使用一层索引:
现在如果我们想查找一个数据,比如说 35,我们首先在索引层遍历,当我们遍历到索引层中值为 20 的结点时,我们发现下一个结点的值为50,所以我们要找的 35 肯定在这两个结点之间。这时我们就通过 20 结点的 down 指针,回到原始链表,然后继续遍历,这个时候我们只需要再遍历两个结点,就能找到我们想要的数据。好我们从头看一下,整个过程我们一共遍历了 5 个结点就找到我们想要的值,如果没有建立索引层,而是用原始链表的话,我们需要遍历 6 个结点。
这种通过对链表加多级索引的结构,就是跳表了。
跳跃表其实也是一种通过“空间来换取时间”的一个算法,令链表的每个结 点不仅记录 next 结点位置,还可以按照 level 层级分别记录后继第 level 个结点。
此法使用的就是“先大步查找确定范围,再逐渐缩小迫近”的思想进行的查找。跳 跃表在算法效率上很接近红黑树。
跳跃表又被称为概率,或者说是随机化的数据结构,目前开源软件 Redis 和 lucence 都有用到它。
在4线程1.6万数据的条件下,ConcurrentHashMap 存取速度是ConcurrentSkipListMap 的4倍左右。
ConcurrentSkipListMap 优势:
1、ConcurrentSkipListMap 的key是有序的。
2、ConcurrentSkipListMap 支持更高的并发。ConcurrentSkipListMap 的存取时间是log(N),和线程数几乎无关。也就是说在数据量一定的情况下,并发的线程越多,ConcurrentSkipListMap越能体现出他的优势。
# 四、ConcurrentLinkedQueue
无界非阻塞队列,它是一个基于链表的无界线程安全队列。该队列的元素 遵循先进先出的原则。头是最先加入的,尾是最近加入的。插入元素是追加到 尾上。提取一个元素是从头提取。
大家可以看成是 LinkedList 的并发版本,常用方法:
concurrentLinkedQueue.add("c");
concurrentLinkedQueue.offer("d"); // 将指定元素插入到此队列的尾部。
concurrentLinkedQueue.peek(); // 检索并不移除此队列的头,如果此队列为 空,则返回 null。
concurrentLinkedQueue.poll(); // 检索并移除此队列的头,如果此队列为空, 则返回 null。
# 五、Collections.synchronizedList(List< T> list)

因为ArrayList实现了RandomAccess接口,因此该方法返回一个SynchronizedRandomAccessList实例。 该类的add实现:

该类的get实现:

通过上面的分析可以看出,无论是读操作还是写操作,它都会进行加锁,当线程的并发级别非常高时就会浪费掉大量的资源,因此某些情况下它并不是一个好的选择。
Collections.synchronizedList和CopyOnWriteArrayList 性能比较:
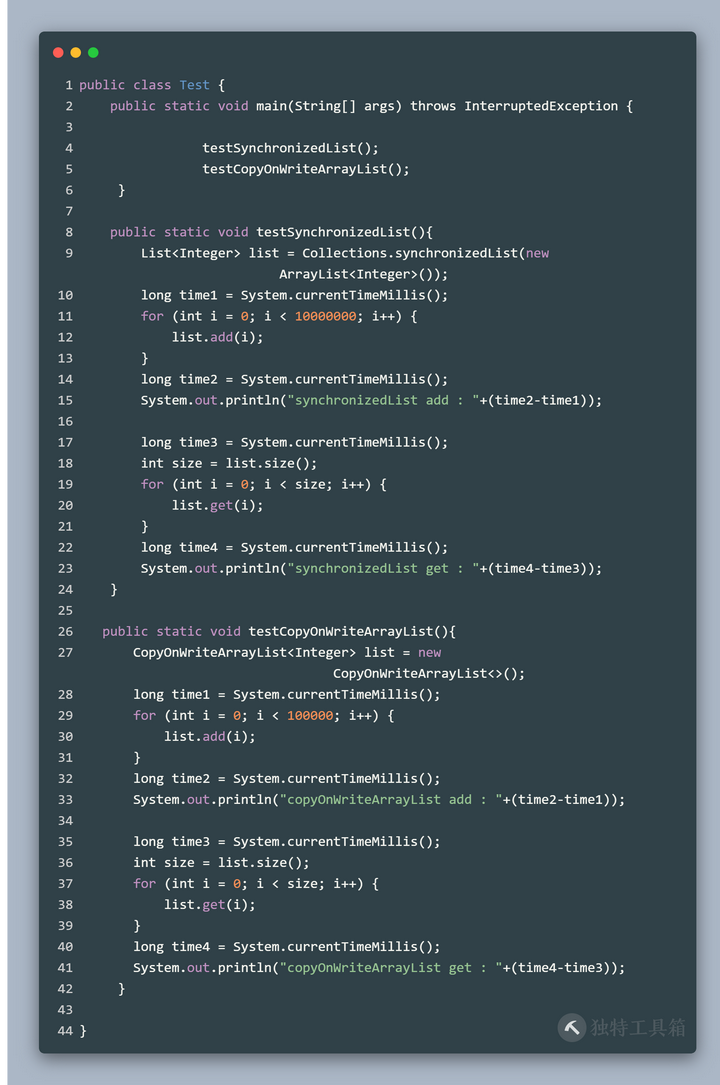
输出结果:
synchronizedList add : 2103 synchronizedList get : 208 copyOnWriteArrayList add : 3820 copyOnWriteArrayList get : 0
读多写少的情况下,推荐使用CopyOnWriteArrayList方式
读少写多的情况下,推荐使用Collections.synchronizedList()的方式
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06