
 java stream 看这一篇文章就够了
java stream 看这一篇文章就够了
# Lambda表达式简介
Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。
Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
使用 Lambda 表达式可以使代码变的更加简洁紧凑。
可以把Lambda表达式理解为简洁的表示可传递的匿名函数的一种方式:它没有名称,但它有参数列表,函数主体,返回类型,可能还有一个可以抛出的异常列表。
# 语法
java中,引入了一个新的操作符“->”,该操作符在很多资料中,称为箭头操作符,或者lambda操作符;箭头操作符将lambda分成了两个部分:
左侧:lambda表达式的参数列表
右侧:lambda表达式中所需要执行的功能,即lambda函数体
(parameters) -> expression
或
(parameters) ->{ statements; }
2
3
4
5
**可选类型声明:**不需要声明参数类型,编译器可以统一识别参数值。
**可选的参数圆括号:**一个参数无需定义圆括号,但多个参数需要定义圆括号。
**可选的大括号:**如果主体包含了一个语句,就不需要使用大括号。
**可选的返回关键字:**如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定表达式返回了一个数值。
语法格式:
A.无参数,无返回值的用法 :() -> System.out.println("hello lambda");
@Test
public void test1() {
Runnable r = new Runnable() {
@Override
public void run() {
System.out.println("hello runnable");
}
};
r.run();
Runnable r1 = () -> System.out.println("hello lambda");
r1.run();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
B.带参函数
// JDK7 匿名内部类写法
List<String> list = Arrays.asList("I", "love", "you", "too");
Collections.sort(list, new Comparator<String>(){// 接口名
@Override
public int compare(String s1, String s2){// 方法名
if(s1 == null)
return -1;
if(s2 == null)
return 1;
return s1.length()-s2.length();
}
});
// JDK8 Lambda表达式写法
List<String> list = Arrays.asList("I", "love", "you", "too");
Collections.sort(list, (s1, s2) ->{// 省略参数表的类型
if(s1 == null)
return -1;
if(s2 == null)
return 1;
return s1.length()-s2.length();
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
C.lambda表达式中,多行语句,分别在无返回值和有返回值的抽象类中的用法
@Test
public void test4() {
// 无返回值lambda函数体中用法
Runnable r1 = () -> {
System.out.println("hello lambda1");
System.out.println("hello lambda2");
System.out.println("hello lambda3");
};
r1.run();
// 有返回值lambda函数体中用法
BinaryOperator<Integer> binary = (x, y) -> {
int a = x * 2;
int b = y + 2;
return a + b;
};
System.out.println(binary.apply(1, 2));// 6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
可以看到,多行的,只需要用大括号{}把语句包含起来就可以了;有返回值和无返回值的,只有一个return的区别;只有一条语句的,大括号和renturn都可以不用写;
D. lambda的类型推断
@Test
public void test5() {
BinaryOperator binary = (Integer x, Integer y) -> x + y;
System.out.println(binary.apply(1, 2));// 3
}
2
3
4
5
6
7
可以看到,在lambda中的参数列表,可以不用写参数的类型,跟java7中 new ArrayList<>(); 不需要指定泛型类型,这样的<>棱形操作符一样,根据上下文做类型的推断
能够使用Lambda的依据是必须有相应的函数接口(函数接口,是指内部只有一个抽象方法的接口)。这一点跟Java是强类型语言吻合,也就是说你并不能在代码的任何地方任性的写Lambda表达式。实际上Lambda的类型就是对应函数接口的类型。Lambda表达式另一个依据是类型推断机制,在上下文信息足够的情况下,编译器可以推断出参数表的类型,而不需要显式指名。Lambda表达更多合法的书写形式如下:
// Lambda表达式的书写形式
Runnable run = () -> System.out.println("Hello World"); // 1
ActionListener listener = event -> System.out.println("button clicked");// 2
Runnable multiLine = () -> {// 3 代码块
System.out.print("Hello");
System.out.println(" Hoolee");
};
BinaryOperator<Long> add = (Long x, Long y) -> x + y;// 4
BinaryOperator<Long> addImplicit = (x, y) -> x + y;// 5 类型推断
2
3
4
5
6
7
8
9
# 函数式接口
函数式接口(Functional Interface)是Java 8对一类特殊类型的接口的称呼。 这类接口只定义了唯一的抽象方法的接口,并且这类接口使用了@FunctionalInterface进行注解。函数式接口可以被隐式转换为 lambda 表达式。在jdk8中,引入了一个新的包java.util.function, 可以使java 8 的函数式编程变得更加简便。这个package中的接口大致分为了以下四类:
Function: 接收参数,并返回结果,主要方法
R apply(T t)Consumer: 接收参数,无返回结果, 主要方法为
void accept(T t)Supplier: 不接收参数,但返回结构,主要方法为
T get()Predicate: 接收参数,返回boolean值,主要方法为
boolean test(T t)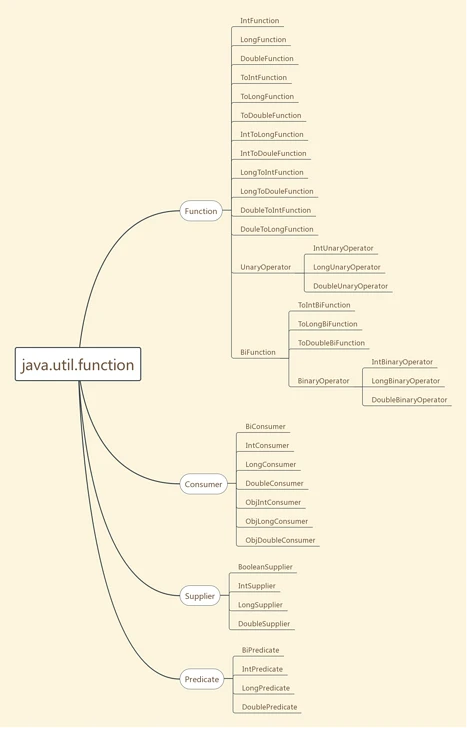
# Function
表示一个方法接收参数并返回结果。
# 接收单个参数
| Interface | functional method | 说明 |
|---|---|---|
| Function<T,R | R apply(T t) | 接收参数类型为T,返回参数类型为R |
| IntFunction | R apply(int value) | 以下三个接口,指定了接收参数类型,返回参数类型为泛型R |
| LongFunction | R apply(long value) | |
| Double | R apply(double value) | |
| ToIntFunction | int applyAsInt(T value) | 以下三个接口,指定了返回参数类型,接收参数类型为泛型T |
| ToLongFunction | long applyAsLong(T value) | |
| ToDoubleFunction | double applyAsDouble(T value) | |
| IntToLongFunction | long applyAsLong(int value) | 以下六个接口,既指定了接收参数类型,也指定了返回参数类型 |
| IntToDoubleFunction | double applyAsLong(int value) | |
| LongToIntFunction | int applyAsLong(long value) | |
| LongToDoubleFunction | double applyAsLong(long value) | |
| DoubleToIntFunction | int applyAsLong(double value) | |
| DoubleToLongFunction | long applyAsLong(double value) | |
| UnaryOperator | T apply(T t) | 特殊的Function,接收参数类型和返回参数类型一样 |
| IntUnaryOperator | int applyAsInt(int left, int right) | 以下三个接口,指定了接收参数和返回参数类型,并且都一样 |
| LongUnaryOperator | long applyAsInt(long left, long right) | |
| DoubleUnaryOperator | double applyAsInt(double left, double right) |
# 接收两个参数
| interface | functional method | 说明 |
|---|---|---|
| BiFunction<T,U,R> | R apply(T t, U u) | 接收两个参数的Function |
| ToIntBiFunction<T,U> | int applyAsInt(T t, U u) | 以下三个接口,指定了返回参数类型,接收参数类型分别为泛型T, U |
| ToLongBiFunction<T,U> | long applyAsLong(T t, U u) | |
| ToDoubleBiFunction<T,U> | double appleyAsDouble(T t, U u) | |
| BinaryOperator | T apply(T t, T u) | 特殊的BiFunction, 接收参数和返回参数类型一样 |
| IntBinaryOperator | int applyAsInt(int left, int right) | |
| LongBinaryOperator | long applyAsInt(long left, long right) | |
| DoubleBinaryOperator | double applyAsInt(double left, double right) |
# Consumer
表示一个方法接收参数但不产生返回值。
# 接收一个参数
| interface | functional method | 说明 |
|---|---|---|
| Consumer | void accept(T t) | 接收一个泛型参数,无返回值 |
| IntConsumer | void accept(int value) | 以下三个类,接收一个指定类型的参数 |
| LongConsumer | void accept(long value) | |
| DoubleConsumer | void accept(double value) |
# 接收两个参数
| interface | functional method | 说明 |
|---|---|---|
| BiConsumer<T,U> | void accept(T t, U u) | 接收两个泛型参数 |
| ObjIntConsumer | void accept(T t, int value) | 以下三个类,接收一个泛型参数,一个指定类型的参数 |
| ObjLongConsumer | void accept(T t, long value) | |
| ObjDoubleConsumer | void accept(T t, double value) |
# Supplier
返回一个结果,并不要求每次调用都返回一个新的或者独一的结果
| interface | functional method | 说明 |
|---|---|---|
| Supplier | T get() | 返回类型为泛型T |
| BooleanSupplier | boolean getAsBoolean() | 以下三个接口,返回指定类型 |
| IntSupplier | int getAsInt() | |
| LongSupplier | long getAsLong() | |
| DoubleSupplier | double getAsDouble() |
# Predicate
根据接收参数进行断言,返回boolean类型
| interface | functional method | 说明 |
|---|---|---|
| Predicate | boolean test(T t) | 接收一个泛型参数 |
| IntPredicate | boolean test(int value) | 以下三个接口,接收指定类型的参数 |
| LongPredicate | boolean test(long value) | |
| DoublePredicate | boolean test(double value) | |
| BiPredicate<T,U> | boolean test(T t, U u) | 接收两个泛型参数,分别为T,U |
自定义函数式接口
@FunctionalInterface
interface GreetingService {
void sayMessage(String message);
}
2
3
4
那么就可以使用Lambda表达式来表示该接口的一个实现(注:JAVA 8 之前一般是用匿名类实现的):
GreetingService greetService1 = message -> System.out.println("Hello " + message);
jdk7写法是这样的
GreetingService greetService1 = new GreetingService() {
@Override
public void sayMessage(String message) {
System.out.println("Hello " + message);
}
};
2
3
4
5
6
# 方法引用
方法引用使用一对冒号 :: 。
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
class Car {
//Supplier是jdk1.8的接口,这里和lamda一起使用了
public static Car create(final Supplier<Car> supplier) {
return supplier.get();
}
public static void collide(final Car car) {
System.out.println("Collided " + car.toString());
}
public void follow(final Car another) {
System.out.println("Following the " + another.toString());
}
public void repair() {
System.out.println("Repaired " + this.toString());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 构造器引用:
它的语法是Class::new,或者更一般的Class< T >::new实例如下:
final Car car = Car.create( Car::new );
final List< Car > cars = Arrays.asList( car );
2
# 静态方法引用
它的语法是Class::static_method,实例如下:
cars.forEach( Car::collide );
# 特定类的任意对象的方法引用
它的语法是Class::method实例如下:
cars.forEach( Car::repair );
2
# 特定对象的方法引用
它的语法是instance::method实例如下:
final Car police = Car.create( Car::new );
cars.forEach( police::follow );
2
# Stream
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
# 什么是 Stream?
Stream(流)是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器generator 等。
- 聚合操作 类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
# 怎么使用Stream?
使用Stream流分为三步:
创建Stream流
通过Stream流对象执行中间操作
执行最终操作,得到结果
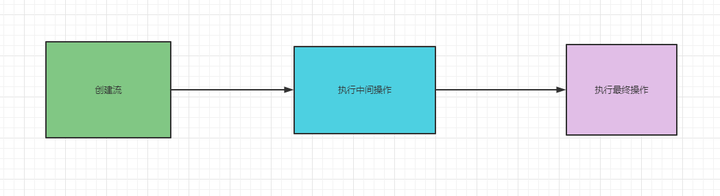
# 创建流
在 Java 8 中, 集合接口有两个方法来生成流:
- stream() − 为集合创建串行流。
- parallelStream() − 为集合创建并行流。
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
List<String> filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());
2
虽然大部分情况下stream是容器调用Collection.stream()方法得到的,但stream和collections有以下不同:
- 无存储。stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。
- 为函数式编程而生。对stream的任何修改都不会修改背后的数据源,比如对stream执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新stream。
- 惰式执行。stream上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。
- 可消费性。stream只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
对stream的操作分为为两类,中间操作(*intermediate operations*)和结束操作(*terminal operations*),二者特点是:
- 中间操作总是会惰式执行,调用中间操作只会生成一个标记了该操作的新stream,仅此而已。
- 结束操作会触发实际计算,计算发生时会把所有中间操作积攒的操作以pipeline的方式执行,这样可以减少迭代次数。计算完成之后stream就会失效。
Stream接口的部分常见方法:
| 操作类型 | 接口方法 |
|---|---|
| 中间操作 | concat() 、distinct()、 filter() 、flatMap()、 limit() 、map() 、peek() 、skip() 、sorted() 、parallel()、 sequential() 、unordered() |
| 结束操作 | allMatch()、 anyMatch() 、collect()、 count()、 findAny() 、findFirst() 、forEach() 、forEachOrdered() 、max() 、min() 、noneMatch() 、reduce()、 toArray() |
区分中间操作和结束操作最简单的方法,就是看方法的返回值,返回值为stream的大都是中间操作,否则是结束操作。
# stream方法使用
# forEach()
我们对forEach()方法并不陌生,在Collection中我们已经见过。方法签名为void forEach(Consumer<? super E> action),作用是对容器中的每个元素执行action指定的动作,也就是对元素进行遍历。
// 使用Stream.forEach()迭代
Stream<String> stream = Stream.of("I", "love", "you", "too");
stream.forEach(str -> System.out.println(str));
2
3
由于forEach()是结束方法,上述代码会立即执行,输出所有字符串。
# filter()

函数原型为Stream<T> filter(Predicate<? super T> predicate),作用是返回一个只包含满足predicate条件元素的Stream。
// 保留长度等于3的字符串
Stream<String> stream= Stream.of("I", "love", "you", "too");
stream.filter(str -> str.length()==3)
.forEach(str -> System.out.println(str));
2
3
4
上述代码将输出为长度等于3的字符串you和too。注意,由于filter()是个中间操作,如果只调用filter()不会有实际计算,因此也不会输出任何信息。
# distinct()

函数原型为Stream<T> distinct(),作用是返回一个去除重复元素之后的Stream。
Stream<String> stream= Stream.of("wo", "are", "family","wo");
stream.distinct()
.forEach(str -> System.out.println(str));
2
3
# sorted()
排序函数有两个,一个是用自然顺序排序,一个是使用自定义比较器排序,函数原型分别为Stream<T> sorted()和Stream<T> sorted(Comparator<? super T> comparator)。
Stream<String> stream= Stream.of("wo", "are", "family");
stream.sorted((str1, str2) -> str1.length()-str2.length())
.forEach(str -> System.out.println(str));
2
3
上述代码将输出按照长度升序排序后的字符串,结果完全在预料之中。
# map()

函数原型为<R> Stream<R> map(Function<? super T,? extends R> mapper),作用是返回一个对当前所有元素执行执行mapper之后的结果组成的Stream。直观的说,就是对每个元素按照某种操作进行转换,转换前后Stream中元素的个数不会改变,但元素的类型取决于转换之后的类型。
Stream<String> stream = Stream.of("I", "love", "you", "too");
stream.map(str -> str.toUpperCase())
.forEach(str -> System.out.println(str));
2
3
上述代码将输出原字符串的大写形式。
# flatMap()

函数原型为<R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper),作用是对每个元素执行mapper指定的操作,并用所有mapper返回的Stream中的元素组成一个新的Stream作为最终返回结果。说起来太拗口,通俗的讲flatMap()的作用就相当于把原stream中的所有元素都"摊平"之后组成的Stream,转换前后元素的个数和类型都可能会改变。
Stream<List<Integer>> stream = Stream.of(Arrays.asList(1,2), Arrays.asList(3, 4, 5));
stream.flatMap(list -> list.stream())
.forEach(i -> System.out.println(i));
2
3
上述代码中,原来的stream中有两个元素,分别是两个List<Integer>,执行flatMap()之后,将每个List都“摊平”成了一个个的数字,所以会新产生一个由5个数字组成的Stream。所以最终将输出1~5这5个数字。
以上简单介绍流的一些简单用法,下面介绍下在集合中常用的操作
# 规约操作
规约操作(reduction operation)又被称作折叠操作(fold),是通过某个连接动作将所有元素汇总成一个汇总结果的过程。元素求和、求最大值或最小值、求出元素总个数、将所有元素转换成一个列表或集合,都属于规约操作。Stream类库有两个通用的规约操作reduce()和collect(),也有一些为简化书写而设计的专用规约操作,比如sum()、max()、min()、count()等。
# reduce()
归约Reduce流运算允许我们通过对序列中的元素重复应用合并操作,从而从元素序列中产生一个单一结果。
reduce操作可以实现从一组元素中生成一个值,sum()、max()、min()、count()等都是reduce操作,将他们单独设为函数只是因为常用。reduce()的方法定义有三种重写形式:
Optional<T> reduce(BinaryOperator<T> accumulator)
T reduce(T identity, BinaryOperator<T> accumulator)
<U> U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
2
3
- 标识identity:代表一个元素,它是归约reduce运算的初始值,如果流为空,则为此默认结果。
- accumulator 累加器:具有两个参数的函数:归约reduce运算后的部分结果和流的下一个元素
- combiner 组合器:当归约是并行化或累加器参数的类型与累加器实现的类型不匹配时,用于合并combine归约操作的部分结果的函数
接口继承关系
Optional<T> reduce(BinaryOperator<T> accumulator);
@FunctionalInterface
public interface BinaryOperator<T> extends BiFunction<T,T,T> {
//两个静态方法,先进行忽略
}
@FunctionalInterface
public interface BiFunction<T, U, R> {
R apply(T t, U u);
//一个默认方法,先进行忽略
}
2
3
4
5
6
7
8
9
10
11
12
方法一 reduce(BinaryOperator accumulator)
//reduce(BinaryOperator<T> accumulator)方法需要一个函数式接口参数`,该函数式接口需要`两个参数`,返回`一个结果`(reduce中
//返回的结果会作为下次累加器计算的第一个参数),也就是`累加器`,最终得到一个`Optional对象
//最长单词
Stream<String> stream1 = Stream.of("we", "are", "family");
Optional<String> longest = stream1.reduce((s1, s2) -> s1.length()>=s2.length() ? s1 : s2);
System.out.println(longest.get()); // family
#等价于
Stream<String> stream1 = Stream.of("we", "are", "family");
Optional<String> longest = stream1.reduce(new BinaryOperator<String>() {
@Override
public String apply(String s1, String s2) {
return s1.length() >= s2.length() ? s1 : s2;
}
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
方法二 reduce(T identity, BinaryOperator accumulator)
identity参数与Stream中数据同类型,相当于一个的初始值,通过累加器accumulator迭代计算Stream中的数据,得到一个跟Stream中数据相同类型的最终结果。
//求和
int s = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(-45, (acc, n) -> acc + n);
System.out.println(s); // 0
//等价于
int s = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(-45, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer acc, Integer n) {
return acc + n;
}
});
2
3
4
5
6
7
8
9
10
11
方法三 reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator combiner)
第一个参数:返回实例u,传递你要返回的U类型对象的初始化实例u
第二个参数:累加器accumulator,可以使用lambda表达式,声明你在u上累加你的数据来源t的逻辑,例如(u,t)->u.sum(t),此时lambda表达式的行参列表是返回实例u和遍历的集合元素t,函数体是在u上累加t
第三个参数:参数组合器combiner,接受lambda表达式。参数的数据类型必须为返回数据类型,该参数主要用于合并多个线程的result值。
// 求单词长度之和
Stream<String> stream = Stream.of("a","bb","ccc");
Integer lengthSum = stream.reduce(0,
(sum, str) -> {
System.out.println("执行BiFunction");
return sum + str.length();
},
(a, b) -> {
System.out.println("执行BinaryOperator");
return a + b;
});
System.out.println(lengthSum);
//等价于
Stream<String> stream = Stream.of("a","bb","ccc");
Integer lengthSum = stream.reduce(0,
new BiFunction<Integer, String, Integer>() {
@Override
public Integer apply(Integer sum, String str) {
System.out.println("执行BiFunction");
return sum + str.length();
}
},
new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer a, Integer b) {
System.out.println("执行BinaryOperator");
return a + b;
}
});
System.out.println(lengthSum);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
输出结果:
执行BiFunction
执行BiFunction
执行BiFunction
6
2
3
4
从输出结果可以看出第三个参数并没有执行。
这是因为Stream是支持并发操作的,为了避免竞争,对于reduce线程都会有独立的result,combiner的作用在于合并每个线程的result得到最终结果。这也说明了了第三个函数参数的数据类型必须为返回数据类型了。
Integer lengthSum = stream.parallel().reduce(0,
(sum, str) -> {
System.out.println("执行BiFunction");
return sum + str.length();
},
(a, b) -> {
System.out.println("执行BinaryOperator");
return a + b;
});
System.out.println(lengthSum);
输出结果
执行BiFunction
执行BiFunction
执行BiFunction
执行BinaryOperator
执行BinaryOperator
6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# collect()
首先定义个实体类
@Data
class Apple {
private String color;
private Integer weight;
}
@Data
class Person {
private String firstName, lastName, job, gender;
private int salary,age;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
collect是一个终端操作,它接收的参数是将流中的元素累积到汇总结果的各种方式(称为收集器)
collect源码
<R, A> R collect(Collector<? super T, A, R> collector);
使用collect()生成Collection
// 将Stream转换成List或Set
Stream<String> stream = Stream.of("a", "bb", "ccc", "ddd");
List<String> list = stream.collect(Collectors.toList());
Set<String> set = stream.collect(Collectors.toSet());
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new));
2
3
4
5
6
7
使用collect()生成Map
Stream<String> stream = Stream.of("a", "bb", "ccc", "ddd");
// 指定key和value
stream.collect(Collectors.toMap(Function.identity(),String::length));
//分组
Map<Integer, List<Person>> map = listPerson1.stream().collect(Collectors.groupingBy(Person::getSalary));
listPerson1.stream().collect(HashMap::new,(maps,p)->maps.put(p.getFirstName(),p.getLastName()),Map::putAll);
//toMap()参数一:key值,参数二:value值 参数三:当两个key值相同时,决定保留前一个value值还是后一个value值,key为null
listPerson1.stream()
.collect(Collectors.toMap(p -> p.getFirstName(), p ->
Optional.ofNullable(p.getLastName()).orElse("value为null加非空检验"), (k1, k2) -> k1));
2
3
4
5
6
7
8
9
10
11
12
13
14
增强版的groupingBy()允许我们对元素分组之后再执行某种运算,比如求和、计数、平均值、类型转换等。这种先将元素分组的收集器叫做上游收集器,之后执行其他运算的收集器叫做下游收集器(downstream Collector)。
//counting方法返回所收集元素的总数
Map<Integer, Long> count = listPerson1.stream().collect(Collectors.groupingBy(Person::getSalary,Collectors.counting()));
//summing方法会对元素求和
Map<Integer, Integer> ageCount = listPerson1.stream().collect(Collectors.groupingBy(Person::getSalary,Collectors.summingInt(Person::getAge)));
//axBy和minBy会接受一个比较器,求最大值,最小值
Map<Integer, Optional<Person>> ageMax = listPerson1.stream().collect(Collectors.groupingBy(Person::getSalary,Collectors.maxBy(Comparator.comparing(Person::getAge))));
//mapping函数会应用到downstream结果上,并需要和其他函数配合使用
Map<Integer, List<String>> nameMap = listPerson1.stream().collect(Collectors.groupingBy(Person::getSalary,Collectors.mapping(Person::getFirstName,Collectors.toList())));
2
3
4
5
6
7
8
9
10
11
12
13
使用collect()做字符串join
String str = Arrays.asList("voidcc.com", "voidmvn.com", "voidtool.com").stream().collect(Collectors.joining(","));
Stream其他用法
//升序
Stream<Integer> sorted = listPerson1.stream().map(Person::getAge).sorted((x, y) -> x.compareTo(y));
//降序
Stream<Integer> sorted = listPerson1.stream().map(Person::getAge).sorted((x, y) -> y.compareTo(x));
//按key升序
map.entrySet().stream().sorted(Comparator.comparing(e -> e.getKey()));
//最大值
Optional<Person> max = listPerson1.stream().max(Comparator.comparing(Person::getAge));
//Map集合转 List
map.entrySet().stream().sorted(Comparator.comparing(e -> e.getKey()))
.map(e -> new Apple(e.getKey(), e.getValue())).collect(Collectors.toList())
.forEach(System.out::println);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06