
 分布式系统基础知识
分布式系统基础知识
# 分布式系统基础知识
一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递 进行通信和协调的系统这是分布式系统,在不同的硬件,不同的软件,不同的网络,不同的计算机上,仅仅通过消 息来进行通讯与协调这是他的特点,更细致的看这些特点又可以有:分布性、对等性、并发性、缺乏全局时钟、 故障随时会发生。
# 分布式系统特性
- 分布性
既然是分布式系统,最显著的特点肯定就是分布性,从简单来看,如果我们做的是个电商项目,整个项目会分成不同的功能,专业点就不同的微服务,比如用户微服务,产品微服务, 订单微服务,这些服务部署在不同的 tomcat 中,不同的服务器中,甚至不同的集群中,整个架构都是分布在不同的地方的,在空间上是随意的,而且随时会增加,删除服务器节点。
- 对等性
对等性是分布式设计的一个目标,还是以电商网站为例,来说明下什么是对等性,要完成一 个分布式的系统架构,肯定不是简单的把一个大的单一系统拆分成一个个微服务,然后部署 在不同的服务器集群就够了,其中拆分完成的每一个微服务都有可能发现问题,而导致整个电商网站出现功能的丢失。
比如订单服务,为了防止订单服务出现问题,一般情况需要有一个备份,在订单服务出现问 题的时候能顶替原来的订单服务。这就要求这两个(或者 2 个以上)订单服务完全是对等的,功能完全是一致的,其实这就是一种服务副本的冗余。还一种是数据副本的冗余,比如数据库,缓存等,都和上面说的订单服务一样,为了安全考 虑需要有完全一样的备份存在,这就是对等性的意思。
- 并发性
并发性其实对我们来说并不模式,在学习多线程的时候已经或多或少学习过,多线程是并发 的基础。但现在我们要接触的不是多线程的角度,而是更高一层,从多进程,多 JVM 的角度,例如在一个分布式系统中的多个节点,可能会并发地操作一些共享资源,如何准确并高效的协调 分布式并发操作。
- 缺乏全局时钟
在分布式系统中,节点是可能反正任意位置的,而每个位置,每个节点都有自己的时间系统, 因此在分布式系统中,很难定义两个事务纠结谁先谁后,原因就是因为缺乏一个全局的时钟序列进行控制,当然,现在这已经不是什么大问题了,已经有大把的时间服务器给系统调用
- 故障随时会发生
任何一个节点都可能出现停电,死机等现象,服务器集群越多,出现故障的可能性就越大, 随着集群数目的增加,出现故障甚至都会成为一种常态,怎么样保证在系统出现故障,而系统还是正常的访问者是作为系统架构师应该考虑的。
# 分布式系统带来的问题
如果把分布式系统和平时的交通系统进行对比,哪怕再稳健的交通系统也会有交通事故,分 布式系统也有很多需要攻克的问题,比如:通讯异常,网络分区,三态,节点故障等。
1、通信异常 通讯异常其实就是网络异常,网络系统本身是不可靠的,由于分布式系统需要通过网络进行 数据传输,网络光纤,路由器等硬件难免出现问题。只要网络出现问题,也就会影响消息的发送与接受过程,因此数据消息的丢失或者延长就会变得非常普遍。
分布式系统需要在各节点之间通信,网络本身是不可靠的,网络中的各个环节,路由器、DNS都是风险因素。即使各节点都正常,其延时也会远大于单机操作。单机内存访问的延时在纳秒数量级,一次网络通信延迟在0.1-1ms,是单机访问的100多倍。如此巨大的延迟差别,会影响消息的收发,消息的丢失和消息延迟变得非常普遍。
2、网络分区
由于网络延迟导致的分布式节点中只有部分能够进行正常通信,另一部分则不能,我们将这种现象叫做网络分区,俗称“脑裂”,当网络分区出现时会存在局部小集群,小集群完成了原来需要全部节点参与的分布式事务请求,这对分布式一致性挑战很大。
网络分区,其实就是脑裂现象,本来有一个交通警察,来管理整个片区的交通情况,一切井然有序,突然出现了停电,或者出现地震等自然灾难,某些道路接受不到交通警察的指令, 可能在这种情况下,会出现一个零时工,片警零时来指挥交通。但注意,原来的交通警察其实还在,只是通讯系统中断了,这时候就会出现问题了,在同一 个片区的道路上有不同人在指挥,这样必然引擎交通的阻塞混乱。这种由于种种问题导致同一个区域(分布式集群)有两个相互冲突的负责人的时候就会出现 这种精神分裂的情况,在这里称为脑裂,也叫网络分区。
3、三态 三态是成功,失败,超时态。
当出现超时现象时,就无法确定请求是否被处理成功。
在一个 jvm 中,应用程序调用一个方法函数后会得到一个明确的相应,要么成功,要么失败, 而在分布式系统中,虽然绝大多数情况下能够接受到成功或者失败的相应,但一旦网络出现异常,就非常有可能出现超时,当出现这样的超时现象,网络通讯的发起方,是无法确定请求是否成功处理的。
4、节点故障 这个其实前面已经说过了,节点故障在分布式系统下是比较常见的问题,指的是组成服务器 集群的节点会出现的宕机或“僵死”的现象,这种现象经常会发生。
随着分布式的出现,传统的单机事务已经无法胜任。如果期望一套严格满足ACID特性的分布式事务,很可能会在系统的可用性和严格一致性上出现冲突。而可用性和一致性都是用户的刚需。为了兼顾可用性和一致性,出现了CAP和BASE这样的经典理论。
# CAP 理论
# CAP理论概述
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
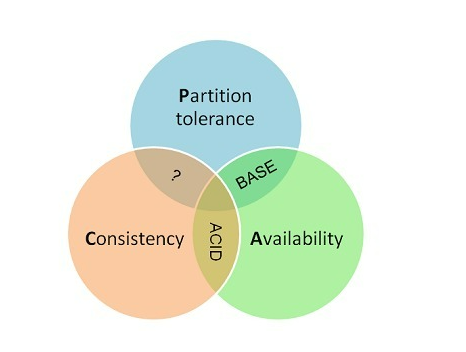
首先看下 CAP,CAP 其实就是一致性,可用性,分区容错性这三个词的缩写
1、一致性
一致性是事务 ACID 的一个特性【原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)】。
这里讲的一致性其实大同小异,只是现在考虑的是分布式环境中,还是不单一的数据库。
对于一个将数据分布到不同的分布式节点的系统来说,当你更新第一个节点的时候,要保证也能够更新第二个节点,不能是用户读第二个节点是出现脏读,这样的系统才是严格一致性的。
一致性指“all nodes see the same data at the same time”,即所有节点在同一时间的数据完全一致。
一致性是因为多个数据拷贝下并发读写才有的问题,因此理解时一定要注意结合考虑多个数据拷贝下并发读写的场景。
在分布式系统中,一致性是数据在多个副本之间是否能够保证一致的特性,这里说的一致性 和前面说的对等性其实差不多。如果能够在分布式系统中针对某一个数据项的变更成功执行 后,所有用户都可以马上读取到最新的值,那么这样的系统就被认为具有【强一致性】。
对于一致性,可以分为从客户端和服务端两个不同的视角。
- 客户端
从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。
- 服务端
从服务端来看,则是更新如何分布到整个系统,以保证数据最终一致。
对于一致性,可以分为强/弱/最终一致性三类
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。
- 强一致性
对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。
- 弱一致性
如果能容忍后续的部分或者全部访问不到,则是弱一致性。
- 最终一致性
如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
2、可用性
可用性指“Reads and writes always succeed”,即服务在正常响应时间内一直可用。
对于用户的每一个请求,都希望在有限的时间内返回结果,有限的时间指的是系统设计的响应时间,返回结果是一个正常的要么成功要么失败的结果,而不是一个用户看不懂的结果。
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。可用性通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。
可用性指系统提供服务必须一直处于可用状态,对于用户的操作请求总是能够在有限的时间内访问结果。这里的重点是【有限的时间】和【返回结果】 为了做到有限的时间需要用到缓存,需要用到负载,这个时候服务器增加的节点是为性能考虑; 为了返回结果,需要考虑服务器主备,当主节点出现问题的时候需要备份的节点能最快的顶替上来,千万不能出现 OutOfMemory 或者其他 500,404 错误,否则这样的系统我们会认为是不可用的。
3、分区容错性
分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。
分布式系统在遇到任何网络分区故障的时候,仍然需要能够对外提供满足一致性和可用性的 服务,除非是整个网络环境都发生了故障。不能出现脑裂的情况。
一个分布式系统不可能同时满足一致性、可用性和分区容错性这三个基本需求,最多只能同时满足其中的两项
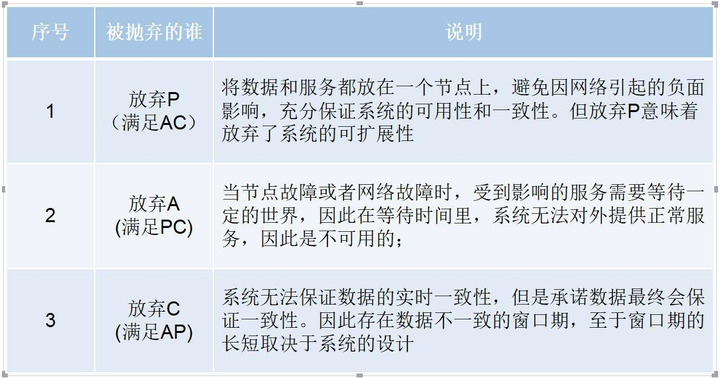
# CAP权衡
通过CAP理论,我们知道无法同时满足一致性、可用性和分区容错性这三个特性,那要舍弃哪个呢?
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。 CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。 AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到N个9,即保证P和A,舍弃C(退而求其次保证最终一致性)。虽然某些地方会影响客户体验,但没达到造成用户流程的严重程度。
对于涉及到钱财这样不能有一丝让步的场景,C必须保证。网络发生故障宁可停止服务,这是保证CA,舍弃P。貌似这几年国内银行业发生了不下10起事故,但影响面不大,报道也不多,广大群众知道的少。还有一种是保证CP,舍弃A。例如网络故障事只读不写。
# 在分布式中CAP理论中的P是一个最基本的要求,因为是分布式,分布式组件必然是部署到不同的节点的。所以我们只要在C和A中找平衡BASE 理论
根据前面的 CAP 理论,架构师应该从一致性和可用性之间找平衡,系统短时间完全不可用肯定是不允许的,那么根据 CAP 理论,在分布式环境下必然也无法做到强一致性。
BASE 理论:即使无法做到强一致性,但分布式系统可以根据自己的业务特点,采用适当的方式来使系统达到最终的一致性;
BASE理论是Basically Available(基本可用),Soft State(软状态)和Eventually Consistent(最终一致性)三个短语的缩写。
Basically Avaliable 基本可用 当分布式系统出现不可预见的故障时,允许损失部分可用性,保障系统的“基本可用”;体 现在“时间上的损失”和“功能上的损失”;
什么是基本可用呢?假设系统,出现了不可预知的故障,但还是能用,相比较正常的系统而言:
- 响应时间上的损失:正常情况下的搜索引擎0.5秒即返回给用户结果,而基本可用的搜索引擎可以在2秒作用返回结果。
- 功能上的损失:在一个电商网站上,正常情况下,用户可以顺利完成每一笔订单。但是到了大促期间,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
Soft state 软状态 其实就是前面讲到的三态,既允许系统中的数据存在中间状态,既系统的不同节点的数据副本之间的数据同步过程存在延时,并认为这种延时不会影响系统可用性;
e.g:12306 网站卖火车票,请求会进入排队队列;
Eventually consistent 最终一致性 上面说软状态,然后不可能一直是软状态,必须有个时间期限。在期限过后,应当保证所有副本保持数据一致性,从而达到数据的最终一致性。这个时间期限取决于网络延时、系统负载、数据复制方案设计等等因素。 e.g:理财产品首页充值总金额短时不一致;
而在实际工程实践中,最终一致性分为5种:
# 因果一致性(Causal consistency)
因果一致性指的是:如果节点A在更新完某个数据后通知了节点B,那么节点B之后对该数据的访问和修改都是基于A更新后的值。于此同时,和节点A无因果关系的节点C的数据访问则没有这样的限制。
# 读己之所写(Read your writes)
读己之所写指的是:节点A更新一个数据后,它自身总是能访问到自身更新过的最新值,而不会看到旧值。其实也算一种因果一致性。
# 会话一致性(Session consistency)
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现 “读己之所写” 的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
# 单调读一致性(Monotonic read consistency)
单调读一致性指的是:如果一个节点从系统中读取出一个数据项的某个值后,那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。
# 单调写一致性(Monotonic write consistency)
单调写一致性指的是:一个系统要能够保证来自同一个节点的写操作被顺序的执行。
总体来说BASE理论面向的是大型高可用、可扩展的分布式系统。与传统ACID特性相反,不同于ACID的强一致性模型,BASE提出通过牺牲强一致性来获得可用性,并允许数据段时间内的不一致,但是最终达到一致状态。同时,在实际分布式场景中,不同业务对数据的一致性要求不一样。因此在设计中,ACID和BASE理论往往又会结合使用。
- 01
- 保姆级教程 用DeepSeek+飞书,批量写文案、写文章,太高效了06-06
- 03
- 熬夜做PPT?AI一键生成高逼格幻灯片,效率提升10倍!06-06